This is my summary of Brembs, Button, and Munafo (2013), “Deep impact: unintended consequences of journal rank.” Main points I took from the paper: 1) Some journals get their “impact factor” through shady means. 2) How does journal rank relate to reliability of results and rate of retractions? 3) Do higher ranking journals publish “better” findings? 4) What should we do if we think journal rank is a bunk measure?
1) How do journals get their impact factor (IF) rank? It’s an account of the number of citations that publications in that journal get per the amount of articles in the journal- and a higher impact factor is seen as more prestigious. Apparently some journals are negotiating their IF and inflating it artificially. There is quite a bit of evidence that some journals inflate their ranking by changing what kinds of articles count for their IF, such as excluding opinion pieces and news editorials. Naturally, if you reduce how many articles count towards the IF but keep the number of citations constant, there will be a stronger ratio of number of citations to number of articles. It gets worse though, as a group of researchers purchased the data from journals in an attempt to manually calculate their impact factor, and are sometimes off by up to 19% of what the journal claims! So even if you know all the info about citations and articles in a journal, you still can’t figure out their IF. Seems kinda fishy.
2) Brembs and colleagues looked at the relation a journal’s rank had on both retraction rates and decline effects. Rate of retractions in the scientific literature have gone from up drastically recently, and now the majority of all retractions are due to scientific misconduct, purposeful or otherwise. They found a strong correlation between a journal’s impact factor and retraction rate (figure 1d):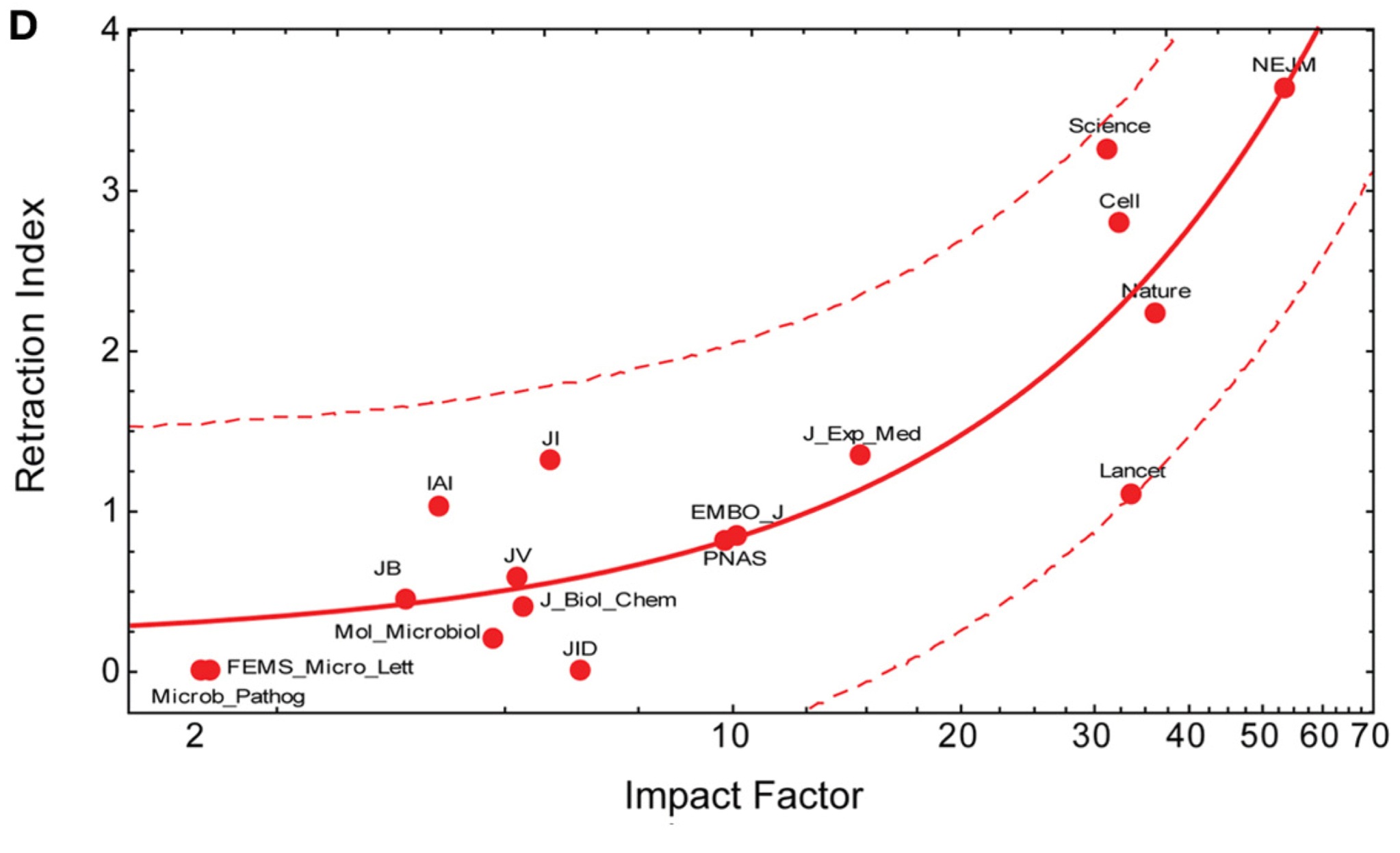
As we can see, as a journal’s impact factor rises so too does it’s rate of retractions. Why this happens is likely a mixture of social pressures- the push for publishing in high journals increases unreliability of findings and higher visibility of papers. If more people see your paper, there is a better chance someone is going to catch you out. A popular case right now is the retraction of a publication in Nature of a novel acid bath procedure that can create certain types of stem cells. It went through 9 months of peer-review, and yet it only took a handful of weeks for it to be retracted once everyone else got their turn at it. It turns out that one of the authors was reproducing figures and results from other work they had done in the past that didn’t get much press.
The decline effect is an observation that some initially strong reported effects (say a drug’s ability to treat cancer) can gradually decline as more studies are done, such that the initial finding is seen as a gross overestimate- and the real effect is estimated to be quite small or even zero. Here I’ve reproduced figure 1b from Brembs et al., showing a plot of the decline of the reported association between carrying a certain gene and your likelihood to succumb to alcoholism. The size of the bubbles indicates the relative journal impact factor and the higher on the y-axis the bubble is, the stronger the reported association. Clearly, as more data come in (from the lower impact journals) there is less and less evidence that the association is as strong as initially reported in the high impact journals. 
So what should we take from this? Clearly there are higher rates of retractions in high impact journals. Additionally, some initial estimates reported in high impact journals lend themselves to a steep decline in their evidential value as smaller impact journals report consistently smaller effects as time goes on. Unfortunately, once the media gets hold of the big initial findings from prominent journals it’s unlikely the smaller estimates from less known journals get anywhere near the same press.
3) There is a perception that higher ranking journals publish more important science. There is a bit of evidence showing that a publication’s perceived importance is tied to it’s publishing journal’s impact factor, and experts rank papers from high impact journals as more important.* However, further investigation shows that journal ranking only accounts for a small amount of a paper’s number of citations (R² = .1 to .3). In other words, publishing in a high impact journal confers a small benefit on the number of citations a paper garners, likely due more to the effects high impact journals have on reading habits than due to the higher quality of the publications.
4) Brembs et al recommend that we stop using journal rank as an assessment tool, and instead “[bring] scholarly communication back to the research institutions … in which both software, raw data and their text descriptions are archived and made accessible (pg 8).” They want us to move away from closed publication that costs up to $2.8 billion annually to a more open evaluation system.
Overall I think they make a strong case that the commonly held assumptions about journal rank are misguided, and we would should be advocating for a more open reporting system. Clearly the pressures of the “publish-or-perish” culture in academia right now are making otherwise good people do shady things (and making it easier for shady people to get away with what they’d do anyways). That’s not to say the people involved aren’t responsible, but there is definitely a culture that encourages subpar methods and behavior. The first step is creating an environment in which people are comfortable publishing “small” effects and where we encourage replication and combination across multiple findings before we make any claims with relative certainty.
*However, in that study they didn’t mask the name of the journal that the papers were published in, so there could be confounding subjective valuations from the experts on the paper’s perceived importance.

[…] journal rank as an assessment tool- we probably shouldn’t do it” https://nicebrain.wordpress.com/2014/03/21/… (about […]