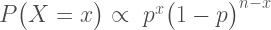[Edit: There is a now-published Bayesian reanalysis of the RPP. See here.]
The Reproducibility Project was finally published this week in Science, and an outpouring of media articles followed. Headlines included “More Than 50% Psychology Studies Are Questionable: Study”, “Scientists Replicated 100 Psychology Studies, and Fewer Than Half Got the Same Results”, and “More than half of psychology papers are not reproducible”.
Are these categorical conclusions warranted? If you look at the paper, it makes very clear that the results do not definitively establish effects as true or false:
After this intensive effort to reproduce a sample of published psychological findings, how many of the effects have we established are true? Zero. And how many of the effects have we established are false? Zero. Is this a limitation of the project design? No. It is the reality of doing science, even if it is not appreciated in daily practice. (p. 7)
Very well said. The point of this project was not to determine what proportion of effects are “true”. The point of this project was to see what results are replicable in an independent sample. The question arises of what exactly this means. Is an original study replicable if the replication simply matches it in statistical significance and direction? The authors entertain this possibility:
A straightforward method for evaluating replication is to test whether the replication shows a statistically significant effect (P < 0.05) with the same direction as the original study. This dichotomous vote-counting method is intuitively appealing and consistent with common heuristics used to decide whether original studies “worked.” (p. 4)
How did the replications fare? Not particularly well.
Ninety-seven of 100 (97%) effects from original studies were positive results … On the basis of only the average replication power of the 97 original, significant effects [M = 0.92, median (Mdn) = 0.95], we would expect approximately 89 positive results in the replications if all original effects were true and accurately estimated; however, there were just 35 [36.1%; 95% CI = (26.6%, 46.2%)], a significant reduction … (p. 4)
So the replications, being judged on this metric, did (frankly) horribly when compared to the original studies. Only 35 of the studies achieved significance, as opposed to the 89 expected and the 97 total. This gives a success rate of either 36% (35/97) out of all studies, or 39% (35/89) relative to the number of studies expected to achieve significance based on power calculations. Either way, pretty low. These were the numbers that most of the media latched on to.
Does this metric make sense? Arguably not, since the “difference between significant and not significant is not necessarily significant” (Gelman & Stern, 2006). Comparing significance levels across experiments is not valid inference. A non-significant replication result can be entirely consistent with the original effect, and yet count as a failure because it did not achieve significance. There must be a better metric.
The authors recognize this, so they also used a metric that utilized confidence intervals over simple significance tests. Namely, does the confidence interval from the replication study include the originally reported effect? They write,
This method addresses the weakness of the first test that a replication in the same direction and a P value of 0.06 may not be significantly different from the original result. However, the method will also indicate that a replication “fails” when the direction of the effect is the same but the replication effect size is significantly smaller than the original effect size … Also, the replication “succeeds” when the result is near zero but not estimated with sufficiently high precision to be distinguished from the original effect size. (p. 4)
So with this metric a replication is considered successful if the replication result’s confidence interval contains the original effect, and fails otherwise. The replication effect can be near zero, but if the CI is wide enough it counts as a non-failure (i.e., a “success”). A replication can also be quite near the original effect but have high precision, thus excluding the original effect and “failing”.
This metric is very indirect, and their use of scare-quotes around “succeeds” is telling. Roughly 47% of confidence intervals in the replications “succeeded” in capturing the original result. The problem with this metric is obvious: Replications with effects near zero but wide CIs get the same credit as replications that were bang on the original effect (or even larger) with narrow CIs. Results that don’t flat out contradict the original effects count as much as strong confirmations? Why should both of these types of results be considered equally successful?
Based on these two metrics, the headlines are accurate: Over half of the replications “failed”. But these two reproducibility metrics are either invalid (comparing significance levels across experiments) or very vague (confidence interval agreement). They also only offer binary answers: A replication either “succeeds” or “fails”, and this binary thinking leads to absurd conclusions in some cases like those mentioned above. Is replicability really so black and white? I will explain below how I think we should measure replicability in a Bayesian way, with a continuous measure that can find reasonable answers with replication effects near zero with wide CIs, effects near the original with tight CIs, effects near zero with tight CIs, replication effects that go in the opposite direction, and anything in between.
A Bayesian metric of reproducibility
I wanted to look at the results of the reproducibility project through a Bayesian lens. This post should really be titled, “A Bayesian …” or “One Possible Bayesian …” since there is no single Bayesian answer to any question (but those titles aren’t as catchy). It depends on how you specify the problem and what question you ask. When I look at the question of replicability, I want to know if is there evidence for replication success or for replication failure, and how strong that evidence is. That is, should I interpret the replication results as more consistent with the original reported result or more consistent with a null result, and by how much?
Verhagen and Wagenmakers (2014), and Wagenmakers, Verhagen, and Ly (2015) recently outlined how this could be done for many types of problems. The approach naturally leads to computing a Bayes factor. With Bayes factors, one must explicitly define the hypotheses (models) being compared. In this case one model corresponds to a probability distribution centered around the original finding (i.e. the posterior), and the second model corresponds to the null model (effect = 0). The Bayes factor tells you which model the replication result is more consistent with, and larger Bayes factors indicate a better relative fit. So it’s less about obtaining evidence for the effect in general and more about gauging the relative predictive success of the original effects. (footnote 1)
If the original results do a good job of predicting replication results, the original effect model will achieve a relatively large Bayes factor. If the replication results are much smaller or in the wrong direction, the null model will achieve a large Bayes factor. If the result is ambiguous, there will be a Bayes factor near 1. Again, the question is which model better predicts the replication result? You don’t want a null model to predict replication results better than your original reported effect.
A key advantage of the Bayes factor approach is that it allows natural grades of evidence for replication success. A replication result can strongly agree with the original effect model, it can strongly agree with a null model, or it can lie somewhere in between. To me, the biggest advantage of the Bayes factor is it disentangles the two types of results that traditional significance tests struggle with: a result that actually favors the null model vs a result that is simply insensitive. Since the Bayes factor is inherently a comparative metric, it is possible to obtain evidence for the null model over the tested alternative. This addresses my problem I had with the above metrics: Replication results bang on the original effects get big boosts in the Bayes factor, replication results strongly inconsistent with the original effects get big penalties in the Bayes factor, and ambiguous replication results end up with a vague Bayes factor.
Bayes factor methods are often criticized for being subjective, sensitive to the prior, and for being somewhat arbitrary. Specifying the models is typically hard, and sometimes more arbitrary models are chosen for convenience for a given study. Models can also be specified by theoretical considerations that often appear subjective (because they are). For a replication study, the models are hardly arbitrary at all. The null model corresponds to that of a skeptic of the original results, and the alternative model corresponds to a strong theoretical proponent. The models are theoretically motivated and answer exactly what I want to know: Does the replication result fit more with the original effect model or a null model? Or as Verhagen and Wagenmakers (2014) put it, “Is the effect similar to what was found before, or is it absent?” (p.1458 here).
Replication Bayes factors
In the following, I take the effects reported in figure 3 of the reproducibility project (the pretty red and green scatterplot) and calculate replication Bayes factors for each one. Since they have been converted to correlation measures, replication Bayes factors can easily be calculated using the code provided by Wagenmakers, Verhagen, and Ly (2015). The authors of the reproducibility project kindly provide the script for making their figure 3, so all I did was take the part of the script that compiled the converted 95 correlation effect sizes for original and replication studies. (footnote 2) The replication Bayes factor script takes the correlation coefficients from the original studies as input, calculates the corresponding original effect’s posterior distribution, and then compares the fit of this distribution and the null model to the result of the replication. Bayes factors larger than 1 indicate the original effect model is a better fit, Bayes factors smaller than 1 indicate the null model is a better fit. Large (or really small) Bayes factors indicate strong evidence, and Bayes factors near 1 indicate a largely insensitive result.
The replication Bayes factors are summarized in the figure below (click to enlarge). The y-axis is the count of Bayes factors per bin, and the different bins correspond to various strengths of replication success or failure. Results that fall in the bins left of center constitute support the null over the original result, and vice versa. The outer-most bins on the left or right contain the strongest replication failures and successes, respectively. The bins labelled “Moderate” contain the more muted replication successes or failures. The two central-most bins labelled “Insensitive” contain results that are essentially uninformative.

So how did we do?
You’ll notice from this crude binning system that there is quite a spread from super strong replication failure to super strong replication success. I’ve committed the sin of binning a continuous outcome, but I think it serves as a nice summary. It’s important to remember that Bayes factors of 2.5 vs 3.5, while in different bins, aren’t categorically different. Bayes factors of 9 vs 11, while in different bins, aren’t categorically different. Bayes factors of 15 and 90, while in the same bin, are quite different. There is no black and white here. These are the categories Bayesians often use to describe grades of Bayes factors, so I use them since they are familiar to many readers. If you have a better idea for displaying this please leave a comment. 🙂 Check out the “Results” section at the end of this post to see a table which shows the study number, the N in original and replications, the r values of each study, the replication Bayes factor and category I gave it, and the replication p-value for comparison with the Bayes factor. This table shows the really wide spread of the results. There is also code in the “Code” section to reproduce the analyses.
Strong replication failures and strong successes
Roughly 20% (17 out of 95) of replications resulted in relatively strong replication failures (2 left-most bins), with resultant Bayes factors at least 10:1 in favor of the null. The highest Bayes factor in this category was over 300,000 (study 110, “Perceptual mechanisms that characterize gender differences in decoding women’s sexual intent”). If you were skeptical of these original effects, you’d feel validated in your skepticism after the replications. If you were a proponent of the original effects’ replicability you’ll perhaps want to think twice before writing that next grant based around these studies.
Roughly 25% (23 out of 95) of replications resulted in relatively strong replication successes (2 right-most bins), with resultant Bayes factors at least 10:1 in favor of the original effect. The highest Bayes factor in this category was 1.3×10^32 (or log(bf)=74; study 113, “Prescribed optimism: Is it right to be wrong about the future?”) If you were a skeptic of the original effects you should update your opinion to reflect the fact that these findings convincingly replicated. If you were a proponent of these effects you feel validation in that they appear to be robust.
These two types of results are the most clear-cut: either the null is strongly favored or the original reported effect is strongly favored. Anyone who was indifferent to these effects has their opinion swayed to one side, and proponents/skeptics are left feeling either validated or starting to re-evaluate their position. There was only 1 very strong (BF>100) failure to replicate but there were quite a few very strong replication successes (16!). There were approximately twice as many strong (10<BF<100) failures to replicate (16) than strong replication successes (7).
Moderate replication failures and moderate successes
The middle-inner bins are labelled “Moderate”, and contain replication results that aren’t entirely convincing but are still relatively informative (3<BF<10). The Bayes factors in the upper end of this range are somewhat more convincing than the Bayes factors in the lower end of this range.
Roughly 20% (19 out of 95) of replications resulted in moderate failures to replicate (third bin from the left), with resultant Bayes factors between 10:1 and 3:1 in favor of the null. If you were a proponent of these effects you’d feel a little more hesitant, but you likely wouldn’t reconsider your research program over these results. If you were a skeptic of the original effects you’d feel justified in continued skepticism.
Roughly 10% (9 out of 95) of replications resulted in moderate replication successes (third bin from the right), with resultant Bayes factors between 10:1 and 3:1 in favor of the original effect. If you were a big skeptic of the original effects, these replication results likely wouldn’t completely change your mind (perhaps you’d be a tad more open minded). If you were a proponent, you’d feel a bit more confident.
Many uninformative “failed” replications
The two central bins contain replication results that are insensitive. In general, Bayes factors smaller than 3:1 should be interpreted only as very weak evidence. That is, these results are so weak that they wouldn’t even be convincing to an ideal impartial observer (neither proponent nor skeptic). These two bins contain 27 replication results. Approximately 30% of the replication results from the reproducibility project aren’t worth much inferentially!
A few examples:
- Study 2, “Now you see it, now you don’t: repetition blindness for nonwords” BF = 2:1 in favor of null
- Study 12, “When does between-sequence phonological similarity promote irrelevant sound disruption?” BF = 1.1:1 in favor of null
- Study 80, “The effects of an implemental mind-set on attitude strength.” BF = 1.2:1 in favor of original effect
- Study 143, “Creating social connection through inferential reproduction: Loneliness and perceived agency in gadgets, gods, and greyhounds” BF = 2:1 in favor of null
I just picked these out randomly. The types of replication studies in this inconclusive set range from attentional blink (study 2), to brain mapping studies (study 55), to space perception (study 167), to cross national comparisons of personality (study 154).
Should these replications count as “failures” to the same extent as the ones in the left 2 bins? Should studies with a Bayes factor of 2:1 in favor of the original effect count as “failures” as much as studies with 50:1 against? I would argue they should not, they should be called what they are: entirely inconclusive.
Interestingly, study 143 mentioned above was recently called out in this NYT article as a high-profile study that “didn’t hold up”. Actually, we don’t know if it held up! Identifying replications that were inconclusive using this continuous range helps avoid over-interpreting ambiguous results as “failures”.
Wrap up
To summarize the graphic and the results discussed above, this method identifies roughly as many replications with moderate success or better (BF>3) as the counting significance method (32 vs 35). (footnote 3) These successes can be graded based on their replication Bayes factor as moderate to very strong. The key insight from using this method is that many replications that “fail” based on the significance count are actually just inconclusive. It’s one thing to give equal credit to two replication successes that are quite different in strength, but it’s another to call all replications failures equally bad when they show a highly variable range. Calling a replication a failure when it is actually inconclusive has consequences for the original researcher and the perception of the field.
As opposed to the confidence interval metric, a replication effect centered near zero with a wide CI will not count as a replication success with this method; it would likely be either inconclusive or weak evidence in favor of the null. Some replications are indeed moderate to strong failures to replicate (36 or so), but nearly 30% of all replications in the reproducibility project (27 out of 95) were not very informative in choosing between the original effect model and the null model.
So to answer my question as I first posed it, are the categorical conclusions of wide-scale failures to replicate by the media stories warranted? As always, it depends.
- If you count “success” as any Bayes factor that has any evidence in favor of the original effect (BF>1), then there is a 44% success rate (42 out of 95).
- If you count “success” as any Bayes factor with at least moderate evidence in favor of the original effect (BF>3), then there is a 34% success rate (32 out of 95).
- If you count “failure” as any Bayes factor that has at least moderate evidence in favor of the null (BF<1/3), then there is a 38% failure rate (36 out of 95).
- If you only consider the effects sensitive enough to discriminate the null model and the original effect model (BF>3 or BF<1/3) in your total, then there is a roughly 47% success rate (32 out of 68). This number jives (uncannily) well with the prediction John Ioannidis made 10 years ago (47%).
However you judge it, the results aren’t exactly great.
But if we move away from dichotomous judgements of replication success/failure, we see a slightly less grim picture. Many studies strongly replicated, many studies strongly failed, but many studies were in between. There is a wide range! Judgements of replicability needn’t be black and white. And with more data the inconclusive results could have gone either way. I would argue that any study with 1/3<BF<3 shouldn’t count as a failure or a success, since the evidence simply is not convincing; I think we should hold off judging these inconclusive effects until there is stronger evidence. Saying “we didn’t learn much about this or that effect” is a totally reasonable thing to do. Boo dichotomization!
Try out this method!
All in all, I think the Bayesian approach to evaluating replication success is advantageous in 3 big ways: It avoids dichotomizing replication outcomes, it gives an indication of the range of the strength of replication successes or failures, and it identifies which studies we need to give more attention to (insensitive BFs). The Bayes factor approach used here can straighten out when a replication shows strong evidence in favor of the null model, strong evidence in favor of the original effect model, or evidence that isn’t convincingly in favor of either position. Inconclusive replications should be targeted for future replication, and perhaps we should look into why these studies that purport to have high power (>90%) end up with insensitive results (large variance, design flaw, overly optimistic power calcs, etc). It turns out that having high power in planning a study is no guarantee that one actually obtains convincingly sensitive data (Dienes, 2014; Wagenmakers et al., 2014).
I should note, the reproducibility project did try to move away from the dichotomous thinking about replicability by correlating the converted effect sizes (r) between original and replication studies. This was a clever idea, and it led to a very pretty graph (figure 3) and some interesting conclusions. That idea is similar in spirit to what I’ve laid out above, but its conclusions can only be drawn from batches of replication results. Replication Bayes factors allow one to compare the original and replication results on an effect by effect basis. This Bayesian method can grade a replication on its relative success or failure even if your reproducibility project only has 1 effect in it.
I should also note, this analysis is inherently context dependent. A different group of studies could very well show a different distribution of replication Bayes factors, where each individual study has a different prior distribution (based on the original effect). I don’t know how much these results would generalize to other journals or other fields, but I would be interested to see these replication Bayes factors employed if systematic replication efforts ever do catch on in other fields.
Acknowledgements and thanks
The authors of the reproducibility project have done us all a great service and I am grateful that they have shared all of their code, data, and scripts. This re-analysis wouldn’t have been possible without their commitment to open science. I am also grateful to EJ Wagenmakers, Josine Verhagen, and Alexander Ly for sharing the code to calculate the replication Bayes factors on the OSF. Many thanks to Chris Engelhardt and Daniel Lakens for some fruitful discussions when I was planning this post. Of course, the usual disclaimer applies and all errors you find should be attributed only to me.
Notes
footnote 1: Of course, a model that takes publication bias into account could fit better by tempering the original estimate, and thus show relative evidence for the bias-corrected effect vs either of the other models; but that’d be answering a different question than the one I want to ask.
footnote 2: I left out 2 results that I couldn’t get to work with the calculations. Studies 46 and 139, both appear to be fairly strong successes, but I’ve left them out of the reported numbers because I couldn’t calculate a BF.
footnote 3: The cutoff of BF>3 isn’t a hard and fast rule at all. Recall that this is a continuous measure. Bayes factors are typically a little more conservative than significance tests in supporting the alternative hypothesis. If the threshold for success is dropped to BF>2 the number of successes is 35 — an even match with the original estimate.
Results
This table is organized from smallest replication Bayes factor to largest (i.e., strongest evidence in favor of null to strongest evidence in favor of original effect). The Ns were taken from the final columns in the master data sheet,”T_N_O_for_tables” and “T_N_R_for_tables”. Some Ns are not integers because they presumably underwent df correction. There is also the replication p-value for comparison; notice that BFs>3 generally correspond to ps less than .05 — BUT there are some cases where they do not agree. If you’d like to see more about the studies you can check out the master data file in the reproducibility project OSF page (linked below).
| Study# N_orig N_rep r_orig r_rep bfRep rep_pval bin # code | |
| 110 278 142 0.55 0.09 3.84E-06 0.277 1 Very strong | |
| 97 73 1486 0.38 -0.04 1.35E-03 0.154 2 Strong | |
| 8 37 31 0.56 -0.11 1.63E-02 0.540 2 Strong | |
| 4 190 268 0.23 -0.01 2.97E-02 0.920 2 Strong | |
| 65 41 131 0.43 0.01 3.06E-02 0.893 2 Strong | |
| 93 83 68 0.32 -0.14 3.12E-02 0.265 2 Strong | |
| 81 90 137 0.27 -0.10 3.24E-02 0.234 2 Strong | |
| 151 41 124 0.40 0.00 4.52E-02 0.975 2 Strong | |
| 7 99 14 0.72 0.13 5.04E-02 0.314 2 Strong | |
| 148 194 259 0.19 -0.03 5.24E-02 0.628 2 Strong | |
| 106 34 45 0.38 -0.22 6.75E-02 0.132 2 Strong | |
| 48 92 192 0.23 -0.05 7.03E-02 0.469 2 Strong | |
| 56 99 38 0.38 -0.04 7.54E-02 0.796 2 Strong | |
| 49 34 86 0.38 -0.03 7.96E-02 0.778 2 Strong | |
| 118 111 158 0.21 -0.05 8.51E-02 0.539 2 Strong | |
| 124 34 68 0.38 -0.03 9.07E-02 0.778 2 Strong | |
| 61 108 220 0.22 0.00 9.56E-02 0.944 2 Strong | |
| 3 24 31 0.42 -0.22 1.03E-01 0.229 3 Moderate | |
| 165 56 51 0.28 -0.18 1.05E-01 0.210 3 Moderate | |
| 149 194 314 0.19 0.02 1.15E-01 0.746 3 Moderate | |
| 87 51 47 0.40 0.01 1.22E-01 0.929 3 Moderate | |
| 155 50 69 0.31 -0.03 1.30E-01 0.778 3 Moderate | |
| 104 236 1146 0.13 0.02 1.59E-01 0.534 3 Moderate | |
| 115 31 8 0.50 -0.45 1.67E-01 0.192 3 Moderate | |
| 72 257 247 0.21 0.04 1.68E-01 0.485 3 Moderate | |
| 68 116 222 0.19 0.00 1.69E-01 0.964 3 Moderate | |
| 64 76 65 0.43 0.11 1.76E-01 0.426 3 Moderate | |
| 136 28 56 0.50 0.10 1.76E-01 0.445 3 Moderate | |
| 129 26 64 0.37 0.02 1.91E-01 0.888 3 Moderate | |
| 39 68 153 0.37 0.10 2.23E-01 0.211 3 Moderate | |
| 20 94 106 0.22 0.02 2.54E-01 0.842 3 Moderate | |
| 53 31 73 0.38 0.08 2.71E-01 0.513 3 Moderate | |
| 153 7 7 0.86 0.12 2.87E-01 0.758 3 Moderate | |
| 58 182 278 0.17 0.04 3.01E-01 0.540 3 Moderate | |
| 150 13 18 0.72 0.21 3.04E-01 0.380 3 Moderate | |
| 140 81 122 0.23 0.04 3.06E-01 0.787 3 Moderate | |
| 63 68 145 0.27 0.07 3.40E-01 0.374 4 Insensitive | |
| 71 373 175 0.22 0.07 3.41E-01 0.332 4 Insensitive | |
| 1 13 28 0.59 0.15 3.49E-01 0.434 4 Insensitive | |
| 5 31 47 0.46 0.13 3.57E-01 0.356 4 Insensitive | |
| 28 31 90 0.34 0.10 4.52E-01 0.327 4 Insensitive | |
| 161 44 44 0.48 0.18 4.56E-01 0.237 4 Insensitive | |
| 2 23 23 0.61 0.23 4.89E-01 0.270 4 Insensitive | |
| 22 93 90 0.22 0.06 5.07E-01 0.717 4 Insensitive | |
| 55 54 68 0.23 0.07 5.33E-01 0.742 4 Insensitive | |
| 154 67 13 0.43 0.11 5.58E-01 0.690 4 Insensitive | |
| 143 108 150 0.17 0.06 5.93E-01 0.678 4 Insensitive | |
| 89 26 26 0.14 0.03 6.81E-01 0.882 4 Insensitive | |
| 167 17 21 0.60 0.25 7.47E-01 0.242 4 Insensitive | |
| 52 131 111 0.21 0.09 8.29E-01 0.322 4 Insensitive | |
| 12 92 232 0.18 0.08 8.97E-01 0.198 4 Insensitive | |
| 43 64 72 0.35 0.16 9.58E-01 0.147 4 Insensitive | |
| 107 84 156 0.22 0.10 9.74E-01 0.189 4 Insensitive | |
| 80 43 67 0.26 0.16 1.24E+00 0.190 5 Insensitive | |
| 86 82 137 0.21 0.12 1.30E+00 0.141 5 Insensitive | |
| 44 67 176 0.35 0.15 1.40E+00 0.045 5 Insensitive | |
| 132 69 41.458 0.25 0.18 1.44E+00 0.254 5 Insensitive | |
| 37 11 17 0.55 0.35 1.59E+00 0.142 5 Insensitive | |
| 26 94 92 0.16 0.14 1.83E+00 0.166 5 Insensitive | |
| 120 28 40 0.38 0.25 1.98E+00 0.053 5 Insensitive | |
| 50 92 103 0.21 0.16 2.22E+00 0.079 5 Insensitive | |
| 146 14 11 0.65 0.50 2.60E+00 0.084 5 Insensitive | |
| 84 52 150 0.50 0.22 2.94E+00 0.008 5 Insensitive | |
| 19 31 19 0.56 0.40 3.01E+00 0.071 6 Moderate | |
| 33 39 39 0.52 0.32 3.20E+00 0.044 6 Moderate | |
| 82 47 41 0.30 0.27 3.21E+00 0.086 6 Moderate | |
| 73 37 120 0.32 0.20 4.55E+00 0.028 6 Moderate | |
| 24 152 48 0.36 0.28 5.32E+00 0.045 6 Moderate | |
| 6 23 31 0.59 0.40 5.89E+00 0.023 6 Moderate | |
| 25 48 63 0.35 0.27 6.65E+00 0.002 6 Moderate | |
| 94 26 59 0.34 0.29 6.73E+00 0.012 6 Moderate | |
| 111 55 116 0.33 0.23 9.22E+00 0.014 6 Moderate | |
| 112 9 9 0.70 0.75 1.17E+01 0.008 7 Strong | |
| 11 21 29 0.67 0.47 1.29E+01 0.008 7 Strong | |
| 133 23 37 0.45 0.42 1.98E+01 0.007 7 Strong | |
| 127 28 25 0.69 0.53 2.40E+01 0.005 7 Strong | |
| 29 7 14 0.74 0.70 3.32E+01 0.002 7 Strong | |
| 32 36 37 0.62 0.48 5.43E+01 0.002 7 Strong | |
| 117 660 660 0.13 0.12 8.57E+01 0.000 7 Strong | |
| 27 31 70 0.38 0.38 1.10E+02 0.001 8 Very strong | |
| 36 20 20 0.71 0.68 1.97E+02 0.000 8 Very strong | |
| 17 76 72.4 0.30 0.43 7.21E+02 0.000 8 Very strong | |
| 15 94 241 0.20 0.25 8.66E+02 0.000 8 Very strong | |
| 116 172 139 0.29 0.32 1.30E+03 0.000 8 Very strong | |
| 114 30 30 0.57 0.65 1.39E+03 0.000 8 Very strong | |
| 158 38 93 0.37 0.41 2.35E+03 0.000 8 Very strong | |
| 145 76 36 0.77 0.65 5.93E+03 0.000 8 Very strong | |
| 13 68 68 0.52 0.52 2.89E+04 0.000 8 Very strong | |
| 122 7 16 0.72 0.92 5.38E+04 0.000 8 Very strong | |
| 10 28 29 0.70 0.78 1.60E+05 0.000 8 Very strong | |
| 121 11 24 0.85 0.83 1.88E+05 0.000 8 Very strong | |
| 135 562 3511.1 0.005 0.11 1.19E+07 0.000 8 Very strong | |
| 134 115 234 0.21 0.50 2.20E+12 0.000 8 Very strong | |
| 142 162 174 0.59 0.61 1.58E+17 0.000 8 Very strong | |
| 113 124 175 0.68 0.76 1.34E+32 0.000 8 Very strong |
R Code
If you want to check/modify/correct my code, here it is. If you find a glaring error please leave a comment below or tweet at me 🙂
| ## from the reproducibility project code here https://osf.io/vdnrb/ | |
| #make sure this file is in your working directory | |
| info <- GET('https://osf.io/fgjvw/?action=download', write_disk('rpp_data.csv', overwrite = TRUE)) #downloads data file from the OSF | |
| MASTER <- read.csv("rpp_data.csv")[1:167, ] | |
| colnames(MASTER)[1] <- "ID" # Change first column name to ID to be able to load .csv file | |
| studies<-MASTER$ID[!is.na(MASTER$T_r..O.) & !is.na(MASTER$T_r..R.)] ##to keep track of which studies are which | |
| studies<-studies[-31]##remove the problem studies (46 and 139) | |
| studies<-studies[-80] | |
| orig<-MASTER$T_r..O.[studies] ##read in the original rs that have matching rep rs | |
| rep<-MASTER$T_r..R.[studies] ##read in the rep rs that have matching original rs | |
| N.R<-MASTER$T_N_R_for_tables[studies] ##n of replications for analysis | |
| N.O<-MASTER$T_N_O_for_tables[studies] ##n of original studies for analysis | |
| p<-MASTER$T_pval_USE..R.[studies] #extract p-values for the studies | |
| bfRep<- numeric(length=95) #prepare for running replications against original study posterior | |
| #download the code for replication functions from here https://osf.io/v7nux/ and load functions into globale environment | |
| for(i in 1:95){ | |
| bfRep[i]<- repBfR0(nOri=N.O[i],rOri=orig[i],nRep=N.R[i],rRep=rep[i]) | |
| } | |
| #bfRep Remove hash to disply BFs | |
| #create bin numbers | |
| bfstrength<-seq(1,8,1) | |
| #create labels for the bins | |
| barlabels<-c("BF<1/100","1/100<BF<1/10","1/10<BF<1/3","1/3<BF<1", "1<BF<3","3<BF<10","10<BF<100","BF>100") | |
| #create category labels to add to bins | |
| g<-c("Very strong","Strong","Moderate","Insensitive","Insensitive", "Moderate","Strong","Very strong") | |
| barlabels<-as.vector(barlabels) | |
| #create new dummy variables for different BFs in the categories | |
| bf<-numeric(length=95) | |
| for(i in 1:95){ | |
| if(bfRep[i]<.001){ #BF<1/100 | |
| bf[i]<-bfstrength[1] | |
| } | |
| if(bfRep[i]<.1 & bfRep[i]>=.001){ #1/100<BF<1/10 | |
| bf[i]<-bfstrength[2] | |
| } | |
| if(bfRep[i]<.3333 & bfRep[i]>=.1){ #1/10<BF<1/3 | |
| bf[i]<-bfstrength[3] | |
| } | |
| if(bfRep[i]<1 & bfRep[i]>=.3333){ #1/3<BF<1 | |
| bf[i]<-bfstrength[4] | |
| } | |
| if(bfRep[i]>1 & bfRep[i]<=3){ #1<BF<3 | |
| bf[i]<-bfstrength[5] | |
| } | |
| if(bfRep[i]>3 & bfRep[i]<=10){ #3<BF<10 | |
| bf[i]<-bfstrength[6] | |
| } | |
| if(bfRep[i]>10 & bfRep[i]<=100){ #10<BF<100 | |
| bf[i]<-bfstrength[7] | |
| } | |
| if(bfRep[i]>100){ #BF>100 | |
| bf[i]<-bfstrength[8] | |
| } | |
| } | |
| table(bf) #shows counts for each bin | |
| #plot the bins | |
| barplot(table(bf),names.arg=barlabels,border="gray80",col="paleturquoise1", | |
| xlab="Replication Bayes Factor Categories",las=1, | |
| main="Bayesian Replication Outcomes from the Reproducibility Project: Psychology", | |
| ylim=c(0,25), sub="BFs > 1 are evidence in favor of the original effect") | |
| arrows(x0=4.8,x1=-.1,y0=21,y1=21,col="red",lwd=5) #replication strength arrow | |
| arrows(x0=5,x1=9.8,y0=21,y1=21,col="darkorchid1",lwd=5) #ditto | |
| text("STRONGER REPLICATION 'FAILURE'",y=22,x=2.5,cex=1.5,col="red") #add text above arrows | |
| text("STRONGER REPLICATION 'SUCCESS'",y=22,x=7.5,cex=1.5,col="darkorchid1") #ditto | |
| text(g,x=c(.7,1.9,3.1,4.3,5.5,6.7,7.9,9.1),y=rep(.5,8)) #add verbal labels to the bottom of bins (e.g., very strong) | |
| k=c(2/95,16/95,20/95,17/95,9/95,8/95,8/95,16/95) #percent of reps in each bin | |
| tab2<-cbind(studies,N.O,N.R,orig,rep,bfRep,p,bf,g) #create matrix of values |
References
Link to the reproducibility project OSF
Link to replication Bayes factors OSF
Dienes, Z. (2014). Using Bayes to get the most out of non-significant results. Frontiers in psychology, 5.
Gelman, A., & Stern, H. (2006). The difference between “significant” and “not significant” is not itself statistically significant. The American Statistician, 60(4), 328-331.
Open Science Collaboration (2015). Estimating the reproducibility of psychological science. Science 28 August 2015: 349 (6251), aac4716 [DOI:10.1126/science.aac4716]
Verhagen, J., & Wagenmakers, E. J. (2014). Bayesian tests to quantify the result of a replication attempt. Journal of Experimental Psychology: General,143(4), 1457.
Wagenmakers, E. J., Verhagen, A. J., & Ly, A. (in press). How to quantify the evidence for the absence of a correlation. Behavior Research Methods.
Wagenmakers, E. J., Verhagen, J., Ly, A., Bakker, M., Lee, M. D., Matzke, D., … & Morey, R. D. (2014). A power fallacy. Behavior research methods, 1-5.