How to become a Bayesian in eight easy steps: An annotated reading list
(TLDR: We wrote an annotated reading list to get you started in learning Bayesian statistics. Published version. Researchgate. PsyArxiv.)
It can be hard to know where to start when you want to learn about Bayesian statistics. I am frequently asked to share my favorite introductory resources to Bayesian statistics, and my go-to answer has been to share a dropbox folder with a bunch of PDFs that aren’t really sorted or cohesive. In some sense I was acting as little more than a glorified Google Scholar search bar.
It seems like there is some tension out there with regard to Bayes, in that many people want to know more about it, but when they pick up, say, Andrew Gelman and colleagues’ Bayesian Data Analysis they get totally overwhelmed. And then they just think, “Screw this esoteric B.S.” and give up because it doesn’t seem like it is worth their time or effort.
I think this happens a lot. Introductory Bayesian texts usually assume a level of training in mathematical statistics that most researchers simply don’t have time (or otherwise don’t need) to learn. There are actually a lot of accessible Bayesian resources out there that don’t require much math stat background at all, but it just so happens that they are not consolidated anywhere so people don’t necessarily know about them.
Enter the eight step program
Beth Baribault, Peter Edelsbrunner (@peter1328), Fabian Dablander (@fdabl), Quentin Gronau, and I have just finished a new paper that tries to remedy this situation, titled, “How to become a Bayesian in eight easy steps: An annotated reading list.” We were invited to submit this paper for a special issue on Bayesian statistics for Psychonomic Bulletin and Review. Each paper in the special issue addresses a specific question we often hear about Bayesian statistics, and ours was the following:
I am a reviewer/editor handling a manuscript that uses Bayesian methods; which articles should I read to get a quick idea of what that means?
So the paper‘s goal is not so much to teach readers how to actually perform Bayesian data analysis — there are other papers in the special issue for that — but to facilitate readers in their quest to understand basic Bayesian concepts. We think it will serve as a nice introductory reading list for any interested researcher.
The format of the paper is straightforward. We highlight eight papers that had a big impact on our own understanding of Bayesian statistics, as well as short descriptions of an additional 28 resources in the Further reading appendix. The first four papers are focused on theoretical introductions, and the second four have a slightly more applied focus.
We also give every resource a ranking from 1–9 on two dimensions: Focus (theoretical vs. applied) and Difficulty (easy vs. hard). We tried to provide a wide range of resources, from easy applications (#14: Wagenmakers, Lee, and Morey’s “Bayesian benefits for the pragmatic researcher”) to challenging theoretical discussions (#12: Edwards, Lindman and Savage’s “Bayesian statistical inference for psychological research”) and others in between.
The figure below (Figure A1, available on the last page of the paper) summarizes our rankings:
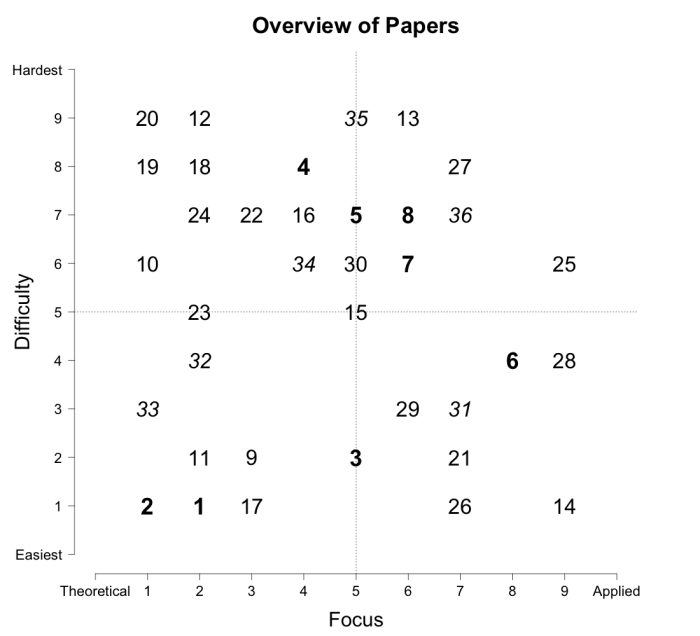
The emboldened numbers (1–8) are the papers that we’ve commented on in detail, numbers in light text (9–30) are papers we briefly describe in the appendix, and the italicized numbers (31–36) are our recommended introductory books (also listed in the appendix).
This is how we chose to frame the paper,
Overall, the guide is designed such that a researcher might be able to read all eight of the highlighted articles and some supplemental readings within a few days. After readers acquaint themselves with these sources, they should be well-equipped both to interpret existing research and to evaluate new research that relies on Bayesian methods.
The list
Here’s the list of papers we chose to cover in detail:
- Lindley (1993): The analysis of experimental data: The appreciation of tea and wine. PDF.
- Kruschke (2015, chapter 2): Introduction: Credibility, models, and parameters. Available on the DBDA website.
- Dienes (2011): Bayesian versus orthodox statistics: Which side are you on? PDF.
- Rouder, Speckman, Sun, Morey, & Iverson (2009): Bayesian t tests for accepting and rejecting the null hypothesis. PDF.
- Vandekerckhove, Matzke, & Wagenmakers (2014): Model comparison and the principle of parsimony. PDF.
- van de Schoot, Kaplan, Denissen, Asendorpf, Neyer, & Aken (2014): A gentle introduction to Bayesian analysis: Applications to developmental research. PDF.
- Lee and Vanpaemel (from the same special issue): Determining priors for cognitive models. PDF.
- Lee (2008): Three case studies in the Bayesian analysis of cognitive models. PDF.
You’ll have to check out the paper to see our commentary and to find out what other articles we included in the Further reading appendix. We provide urls (web archived when possible; archive.org/web/) to PDFs of the eight main papers (except #2, that’s on the DBDA website), and wherever possible for the rest of the resources (some did not have free copies online; see the References).
I thought this was a fun paper to write, and if you think you might want to learn some Bayesian basics I hope you will consider reading it.
Oh, and I should mention that we wrote the whole paper collaboratively on Overleaf.com. It is a great site that makes it easy to get started using LaTeX, and I highly recommend trying it out.
This is the fifth post in the Understanding Bayes series. Until next time,


[…] FMRIF: fmri summer course WashU: Evolutionary Psych Neuroskeptic: Quick MRI tutorial Bayesian: Link Little book of R: multivariate […]
[…] From: https://alexanderetz.com/2016/02/07/understanding-bayes-how-to-become-a-bayesian-in-eight-easy-steps/ […]
Super useful. I’m just getting a grasp of Bayesian concepts. I want to introduce them in under-graduate courses Market Research, but first I must understand the nuts & bolts.
I don’t want to just be a Bayesian, I want to be a Bayesian Empirimancer. http://dresdencodak.com/2009/01/27/advanced-dungeons-and-discourse/
[…] Understanding Bayes: How to become a Bayesian in eight easy steps It can be hard to know where to start when you want to learn about Bayesian statistics. I am frequently asked to share my favorite introductory resources to Bayesian statistics, and my go-to answer has been to share a dropbox folder with a bunch of PDFs that aren’t really sorted or cohesive. In some sense I was acting as little more than a glorified Google Scholar search bar. […]
[…] Etz just wrote a really elegant blog post about his recent paper with Beth Baribault, Peter Edelsbrunner (@peter1328), Fabian Dablander […]
[…] https://alexanderetz.com/2016/02/07/understanding-bayes-how-to-become-a-bayesian-in-eight-easy-steps/ […]
[…] Tham khảo thêm: Understanding Bayes: How to become a Bayesian in eight easy steps […]
An additional reply: I actually started this Bayesian “crash course”. I have collected/printed the course material (the articles) and am reading them now. I’m looking forward to reading your posts on these articles. So – keep ’em coming !!
Great! The paper is still not in its final form (still in the submission pipeline), so we would welcome any feedback you have as you go through it.
First, compliments on the paper, this is really a good idea and thanks to all authors for all the effort that was put into it. Some minor remarks:
– the text might be better readable if you would include graphs or tables from the original papers that you refer to. That would make it easier for readers, they wouldn’ t have to keep a copy of the original article at hand.
– perhaps it could be indicated at the beginning of the paper what the entry level is; what statistical knowlegde you assume in your readers
– the text seems to be written for ‘beginners’, yet some parts (e.g. the criticism that p-values depend on not observed data in not done experiments) assume some knowlegde of, in this case, the frequentist methods.
– perhaps (I’m thinking out loud here) the paper could use a ‘balanced’ overview of the pros and cons of frequentism and bayesianism? The message to frequentists is then not “your method sucks” but “your method is sound, but not for this type of problem”. Reasoning from hypothesis to data can be useful, but most of the time we are interested to learn what one particular observed set of data is telling us. Again, I’m just thinking here, I’m sure you had this discussion already.
This is awesome and I’m really looking forward to reading this paper, but in order to improve the Google search situation and help people find this single great reference to understanding Bayes, the paper should (also) be published in plain HTML that can be indexed and linked to properly and not just a binary PDF blob.
[…] the great response to the eight easy steps paper we posted, I have decided to start a recurring series, where each week I highlight one of the papers that we […]
[…] a skeptical perspective on religious priming – fifty million frenchmen can eat it – Understanding Bayes: How to become a Bayesian in eight easy steps – A Variant on “Statistically Controlling for Confounding Constructs is Harder than you […]
[…] the great response to the eight easy steps paper we posted, I started a recurring series, where each week I highlight one of the papers that we included in […]
Reblogged this on The Ratliff Notepad.
[…] Understanding Bayes: How to become a Bayesian in eight easy steps […]
[…] Understanding Bayes […]
Alex-
Thanks for putting this list together. I’m trying to learn about Bayesian stats, and as you suggest I’ve found that although a lot of people want me to use Bayesian methods, they’re not always very good at helping me be able to do that.
I’m reading the first paper on your list, Lindley 1993, and have hit a point in the first section, on the tea experiment, that seems to me to be incorrect. This is the section called “A Criticism” in which Lindley argues that it doesn’t make sense that what he calls a fixed approach and a sequential approach would not give the same p-values if the sample size of both is 6. But I can’t see why they *would* be expected to have the same p-value since there are fundamental differences in the sampling approach. In the fixed experiment, we can get to 5 out of 6 positive outcomes through any ordering of the 5 positive and one negative outcomes, whereas in the sequential experiment the only way to get to a sample of size 6 is to have the first five outcomes be positive. Since this basically switches us from a combination to a permutation, I don’t understand why we would consider the probabilities to be equivalent. Am I missing something?
Thanks,
Alistair
Hi Alistair,
Thanks very much for reading. You may find the fact that different sampling plans change the p value intuitive and obvious, but many researchers are quite surprised to find this out. Lindley’s criticism is that the conclusion one draws from the data depend on knowing the intentions with this the data were collected.
To clarify: The criticism is not that the p value changes with different sampling schemes; that must happen because of the way they are defined. But if one bases conclusions on the p value then the conclusions drawn depend on all sorts of irrelevant details about the data collection process.
[…] Made more changes based on the very helpful comments by Alexander Etz (read his blog, especially how to become a Bayesian in eight easy steps). Changes summarized in the Conclusions section. Also added two references, in case you want to […]
[…] type of research. As most will already be familiar with frequentist statistics, here is a guide on becoming a Bayesian eight easy steps. Sadly, this discussion can sometimes results in a bitter fight with two camps slinging feces at […]
[…] become a Bayesian in eight easy steps: An annotated reading list” that we initially submitted earlier this year. You can find an updated preprint here. The reviewer comments were pleasantly positive (and they […]
[…] deserves to be highlighted. For instance, there is the “meta-tutorial” by Alex Etz and others, “How to become a Bayesian in eight easy steps: An annotated reading list”. Etz et al. discuss a host of accessible articles and books on Bayesian inference. This is all the […]