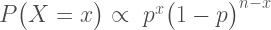In this installment of Understanding Bayes I want to discuss the nature of Bayesian evidence and conclusions. In a previous post I focused on Bayes factors’ mathematical structure and visualization. In this post I hope to give some idea of how Bayes factors should be interpreted in context. How do we use the Bayes factor to come to a conclusion?
How to calculate a Bayes factor
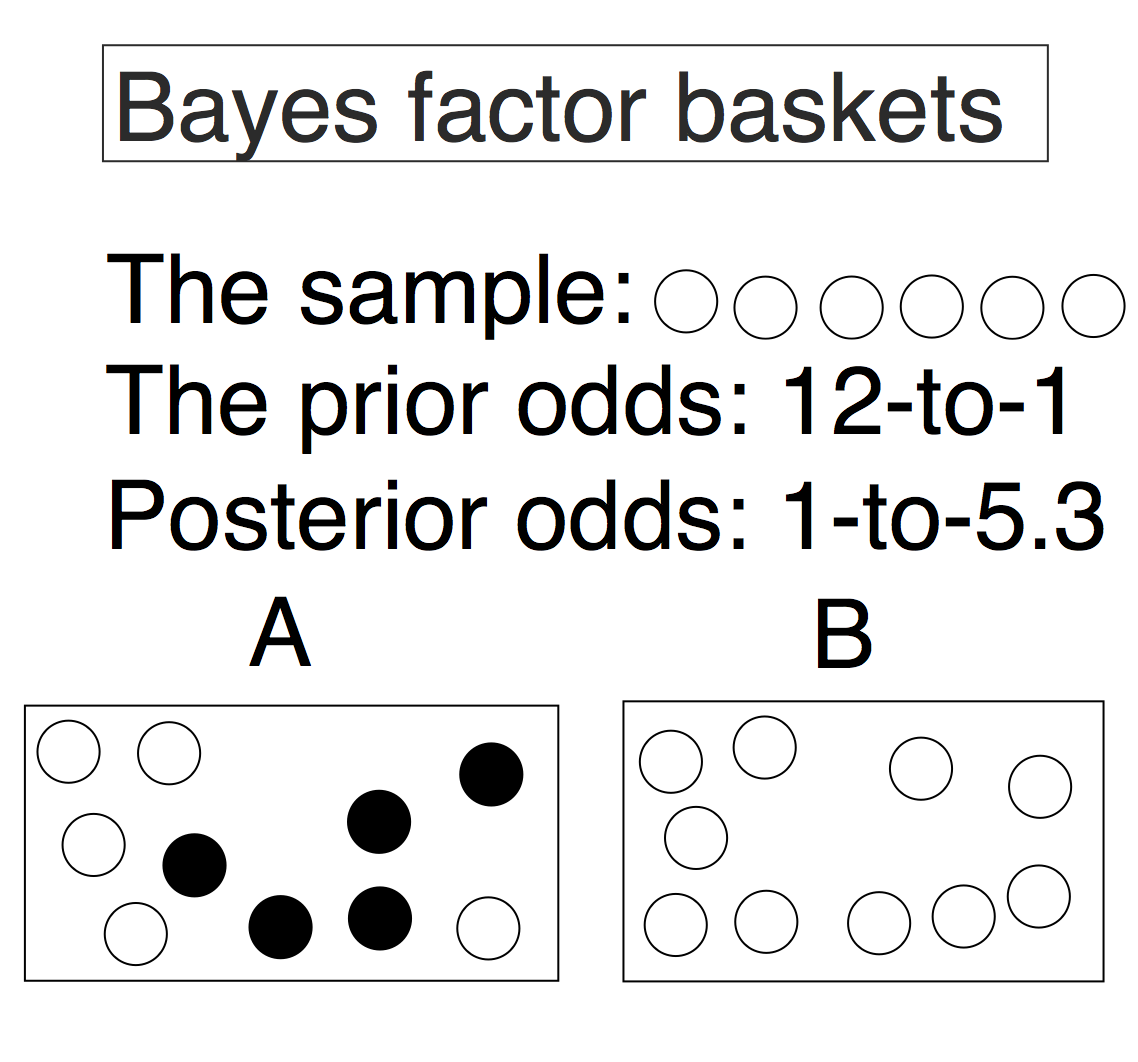
I’m going to start with an example to show the nature of the Bayes factor. Imagine I have 2 baskets with black and white balls in them. In basket A there are 5 white balls and 5 black balls. In basket B there are 10 white balls. Other than the color, the balls are completely indistinguishable. Here’s my advanced high-tech figure depicting the problem.

You choose a basket and bring it to me. The baskets aren’t labeled so I can’t tell by their appearance which one you brought. You tell me that in order to figure out which basket I have, I am allowed to take a ball out one at a time and then return it and reshuffle the balls around. What outcomes are possible here? In this case it’s super simple: I can either draw a white ball or a black ball.
If I draw a black ball I immediately know I have basket A, since this is impossible in basket B. If I draw a white ball I can’t rule anything out, but drawing a white ball counts as evidence for basket B over basket A. Since the white ball occurs with probability 1 if I have basket B, and probability .5 if I have basket A, then due to what is known as the Likelihood Axiom, I have evidence for basket B over basket A by a factor of 2. See this post for a refresher on likelihoods, including the concepts such as the law of likelihood and the likelihood principle. The short version is that observations count as evidence for basket B over basket A if they are more probable given basket B than basket A.

I continue to sample, and end up with this set of observations: {W, W, W, W, W, W}. Each white ball that I draw counts as evidence of 2 for basket B over basket A, so my evidence looks like this: {2, 2, 2, 2, 2, 2}. Multiply them all together and my total evidence for B over A is 2^6, or 64. This interpretation is simple: The total accumulated data are, all together, 64 times more probable under basket B than basket A. This number represents a simple Bayes factor, or likelihood ratio.
How to interpret a Bayes factor
In one sense, the Bayes factor always has the same interpretation in every problem: It is a ratio formed by the probability of the data under each hypothesis. It’s all about prediction. The bigger the Bayes factor the more one hypothesis outpredicted the other.
But in another sense the interpretation, and our reaction, necessarily depends on the context of the problem, and that is represented by another piece of the Bayesian machinery: The prior odds. The Bayes factor is the factor by which the data shift the balance of evidence from one hypothesis to another, and thus the amount by which the prior odds shift to posterior odds.
Imagine that before you brought me one of the baskets you told me you would draw a card from a standard, shuffled deck of cards. You have a rule: Bring me basket B if the card drawn is a black suit and bring basket A if it is a red suit. You pick a card and, without telling me what it was, bring me a basket. Which basket did you bring me? What information do I have about the basket before I get to draw a sample from it?
I know that there is a 50% chance that you choose a black card, so there is a 50% chance that you bring me basket B. Likewise for basket A. The prior probabilities in this scenario are 50% for each basket, so the prior odds for basket A vs basket B are 1-to-1. (To calculate odds you just divide the probability of one hypothesis by the other.)

Let’s say we draw our sample and get the same results as before: {W, W, W, W, W, W}. The evidence is the same: {2, 2, 2, 2, 2, 2} and the Bayes factor is the same, 2^6=64. What do we conclude from this? Should we conclude we have basket A or basket B?
The conclusion is not represented by the Bayes factor, but by the posterior odds. The Bayes factor is just one piece of the puzzle, namely the evidence contained in our sample. In order to come to a conclusion the Bayes factor has to be combined with the prior odds to obtain posterior odds. We have to take into account the information we had before we started sampling. I repeat: The posterior odds are where the conclusion resides. Not the Bayes factor.
Posterior odds (or probabilities) and conclusions
In the example just given, the posterior odds happen to equal the Bayes factor. Since the prior odds were 1-to-1, we multiply by the Bayes factor of 1-to-64, to obtain posterior odds of 1-to-64 favoring basket B. This means that, when these are the only two possible baskets, the probability of basket A has shrunk from 50% to 2% and the probability of basket B has grown from 50% to 98%. (To convert odds to probabilities divide the odds by odds+1.) This is the conclusion, and it necessarily depends on the prior odds we assign.

Say you had a different rule for picking the baskets. Let’s say that this time you draw a card and bring me basket B if you draw a King (of any suit) and you bring me basket A if you draw any other card. Now the prior odds are 48-to-4, or 12-to-1, in favor of basket A.
The data from our sample are the same, {W, W, W, W, W, W}, and so is the Bayes factor, 2^6= 64. The conclusion is qualitatively the same, with posterior odds of 1-to-5.3 that favor basket B. This means that, again when considering these as the only two possible baskets, the probability of basket A has been shrunk from 92% to 16% and the probability of basket B has grown from 8% to 84%. The Bayes factor is the same, but we are less confident in our conclusion. The prior odds heavily favored basket A, so it takes more evidence to overcome this handicap and reach as strong a conclusion as before.

What happens when we change the rule once again: Bring me basket B if you draw a King of Hearts and basket A if you draw any other card. Now the prior odds are 51-to-1 in favor of basket A. The data are the same again, and the Bayes factor is still 64. Now the posterior odds are 1-to-1.3 in favor of basket B. This means that the probability of basket A has been shrunk from 98% to 43% and the probability of basket B has grown from 2% to 57%. The evidence, and the Bayes factor, is exactly the same — but the conclusion is totally ambiguous.

Evidence vs. Conclusions
In each case I’ve considered, the evidence has been exactly the same: 6 draws, all white. As a corollary to the discussion above, if you try to come to conclusions based only on the Bayes factor then you are implicitly assuming prior odds of 1-to-1. I think this is unreasonable in most circumstances. When someone looks at a medium-to-large Bayes factor in a study claiming “sadness impairs color perception” (or some other ‘cute’ metaphor study published in Psych Science) and thinks, “I don’t buy this,” they are injecting their prior odds into the equation. Their implicit conclusion is: “My posterior odds for this study are not favorable.” This is the conclusion. The Bayes factor is not the conclusion.
Many studies follow-up on earlier work, so we might give favorable prior odds; thus, when we see a Bayes factor of 5 or 10 we “buy what the study is selling,” so to speak. Or the study might be testing something totally new, so we might give unfavorable prior odds; thus, when we see a Bayes factor of 5 or 10 we remain skeptical. This is just another way of saying that we may reasonably require more evidence for extraordinary claims.
When to stop collecting data
It also follows from the above discussion that sometimes enough is enough. What I mean is that sometimes the conclusion for any reasonable prior odds assignment is strong enough that collecting more data is not worth the time, money, or energy. In the Bayesian framework the stopping rules don’t affect the Bayes factor, and subsequently they don’t affect the posterior odds. Take the second example above, where you gave me basket B if you drew any King. I had prior odds of 12-to-1 in favor of basket A, drew 6 white balls in a row, and ended up with 1-to-5.3 posterior odds in favor of basket B. This translated to a posterior probability of 84% for basket B. If I draw 2 more balls and they are both white, my Bayes factor increases to 2^8=256 (and this should not be corrected for multiple comparisons or so-called “topping up”). My posterior odds increase to roughly 1-to-21 in favor of basket B, and the probability for basket B shoots up from 84% to 99%. I would say that’s enough data for me to make a firm conclusion. But someone else might have other relevant information about the problem I’m studying, and they can come to a different conclusion.
Conclusions are personal
There’s no reason another observer has to come to the same conclusion as me. She might have talked to you and you told her that you actually drew three cards (with replacement and reshuffle) and that you would only have brought me basket B if you drew three kings in a row. She has different information than I do, so naturally she has different prior odds (1728-to-1 in favor of basket A). She would come to a different conclusion than I would, namely that I was actually probably sampling from basket A — her posterior odds are roughly 7-to-1 in favor of basket A. We use the same evidence, a Bayes factor of 2^8=256, but come to different conclusions.
Conclusions are personal. I can’t tell you what to conclude because I don’t know all the information you have access to. But I can tell you what the evidence is, and you can use that to come to your own conclusion. In this post I used a mechanism to generate prior odds that are intuitive and obvious, but we come to our scientific judgments through all sorts of ways that aren’t always easily expressed or quantified. The idea is the same however you come to your prior odds: If you’re skeptical of a study that has a large Bayes factor, then you assigned it strongly unfavorable prior odds.
This is why I, and other Bayesians, advocate for reporting the Bayes factor in experiments. It is not because it tells someone what to conclude from the study, but that it lets them take the information contained in your data to come to their own conclusion. When you report your own Bayes factors for your experiments, in your discussion you might consider how people with different prior odds will react to your evidence. If your Bayes factor is not strong enough to overcome a skeptic’s prior odds, then you may consider collecting more data until it is. If you’re out of resources and the Bayes factor is not strong enough to overcome the prior odds of a moderate skeptic, then there is nothing wrong with acknowledging that other people may reasonably come to different conclusions about your study. Isn’t that how science works?
Bottom line
If you want to come to a conclusion you need the posterior. If you want to make predictions about future sampling you need the posterior. If you want to make decisions you need the posterior (and a utility function; a topic for future blog). If you try to do all this with only the Bayes factor then you are implicitly assuming equal prior odds — which I maintain are almost never appropriate. (Insofar as you do ignore the prior and posterior, then do not be surprised when your Bayes factor simulations find strange results.) In the Bayesian framework each piece has its place. Bayes factors are an important piece of the puzzle, but they are not the only piece. They are simply the most basic piece from my perspective (after the sum and product rules) because they represent the evidence you accumulated in your sample. When you need to do something other than summarize evidence you have to expand your statistical arsenal.
For more introductory material on Bayesian inference, see the Understanding Bayes hub here.
Technical caveat
It’s important to remember that everything is relative and conditional in the Bayesian framework. The posterior probabilities I mention in this post are simply the probabilities of the baskets under the assumption that those are the only relevant hypotheses. They are not absolute probabilities. In other words, instead of writing the posterior probability as P(H|D), it should really be written P(H|D,M), where M is the conditional that the only hypotheses considered are in the following model index: M= {A, B, … K). This is why I personally prefer to use odds notation, since it makes the relativity explicit.