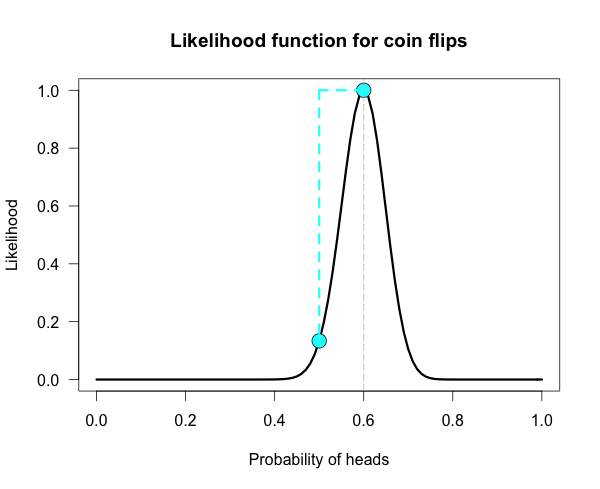
No! If you are like most of the sane researchers out there, you don’t spend your days and nights worrying about the nuances of different statistical concepts. Especially ones as traditional as these. But there is one concept that I think we should all be aware of: P-values mean very different things to different people. Richard Royall (1997, p. 76-7) provides a smattering of different possible interpretations and fleshes out the arguments for why these mixed interpretations are problematic (much of this post comes from his book):
In the testing process the null hypothesis either is rejected or is not rejected. If the null hypothesis is not rejected, we will say that the data on which the test is based do not provide sufficient evidence to cause rejection. (Daniel, 1991, p. 192)
A nonsignificant result does not prove that the null hypothesis is correct — merely that it is tenable — our data do not give adequate grounds for rejecting it. (Snedecor and Cochran, 1980, p. 66)
The verdict does not depend on how much more readily some other hypothesis would explain the data. We do not even start to take that question seriously until we have rejected the null hypothesis. …..The statistical significance level is a statement about evidence… If it is small enough, say p = 0.001, we infer that the result is not readily explained as a chance outcome if the null hypothesis is true and we start to look for an alternative explanation with considerable assurance. (Murphy, 1985, p. 120)
If [the p-value] is small, we have two explanations — a rare event has happened, or the assumed distribution is wrong. This is the essence of the significance test argument. Not to reject the null hypothesis … means only that it is accepted for the moment on a provisional basis. (Watson, 1983)
Test of hypothesis. A procedure whereby the truth or falseness of the tested hypothesis is investigated by examining a value of the test statistic computed from a sample and then deciding to reject or accept the tested hypothesis according to whether the value falls into the critical region or acceptance region, respectively. (Remington and Schork, 1970, p. 200)
Although a ‘significant’ departure provides some degree of evidence against a null hypothesis, it is important to realize that a ‘nonsignificant’ departure does not provide positive evidence in favour of that hypothesis. The situation is rather that we have failed to find strong evidence against the null hypothesis. (Armitage and Berry, 1987, p. 96)
If that value [of the test statistic] is in the region of rejection, the decision is to reject H0; if that value is outside the region of rejection, the decision is that H0 cannot be rejected at the chosen level of significance … The reasoning behind this decision process is very simple. If the probability associated with the occurance under the null hypothesis of a particular value in the sampling distribution is very small, we may explain the actual occurrence of that value in two ways; first we may explain it by deciding that the null hypothesis is false or, second, we may explain it by deciding that a rare and unlikely event has occurred. (Siegel and Castellan, 1988, Chapter 2)
These all mix and match three distinct viewpoints with regard to hypothesis tests: 1) Neyman-Pearson decision procedures, 2) Fisher’s p-value significance tests, and 3) Fisher’s rejection trials (I think 2 and 3 are sufficiently different to be considered separately). Mixing and matching them is inappropriate, as will be shown below. Unfortunately, they all use the same terms so this can get confusing! I’ll do my best to keep things simple.
1. Neyman-Pearson (NP) decision procedure:
Neyman describes it thusly:
The problem of testing a statistical hypothesis occurs when circumstances force us to make a choice between two courses of action: either take step A or take step B… (Neyman 1950, p. 258)
…any rule R prescribing that we take action A when the sample point … falls within a specified category of points, and that we take action B in all other cases, is a test of a statistical hypothesis. (Neyman 1950, p. 258)
The terms ‘accepting’ and ‘rejecting’ a statistical hypothesis are very convenient and well established. It is important, however, to keep their exact meaning in mind and to discard various additional implications which may be suggested by intuition. Thus, to accept a hypothesis H means only to take action A rather than action B. This does not mean that we necessarily believe that the hypothesis H is true. Also if the application … ‘rejects’ H, this means only that the rule prescribes action B and does not imply that we believe that H is false. (Neyman 1950, p. 259)
So what do we take from this? NP testing is about making a decision to choose H0 or H1, not about shedding light on the truth of any one hypothesis or another. We calculate a test statistic, see where it lies with regard to our predefined rejection regions, and make the corresponding decision. We can assure that we are not often wrong by defining Type I and Type II error probabilities (α and β) to be used in our decision procedure. According to this framework, a good test is one that minimizes these long-run error probabilities. It is important to note that this procedure cannot tell us anything about the truth of hypotheses and does not provide us with a measure of evidence of any kind, only a decision to be made according to our criteria. This procedure is notably symmetric — that is, we can either choose H0 or H1.
Test results would look like this:
α and β were prespecified -based on relevant costs associated with the different errors- for this situation at yadda yadda yadda. The test statistic (say, t=2.5) falls inside the rejection region for H0 defined as t>2.0 so we reject H0 and accept H1.” (Alternatively, you might see “p < α = x so we reject H0. The exact value of p is irrelevant, it is either inside or outside of the rejection region defined by α. Obtaining a p = .04 is effectively equivalent to p = .001 for this procedure, as is obtaining a result very much larger than the critical t above.)
2. Fisher’s p-value significance tests
Fisher’s first procedure is only ever concerned with one hypothesis- that being the null. This procedure is not concerned with making decisions (and when in science do we actually ever do that anyway?) but with measuring evidence against the hypothesis. We want to evaluate ‘the strength of evidence against the hypothesis’ (Fisher, 1958, p.80) by evaluating how rare our particular result (or even bigger results) would be if there were really no effect in the study. Our objective here is to calculate a single number that Fisher called the level of significance, or the p-value. Smaller p is more evidence against the hypothesis than larger p. Increasing levels of significance* are often represented** by more asterisks*** in tables or graphs. More asterisks mean lower p-values, and presumably more evidence against the null.
What is the rationale behind this test? There are only two possible interpretations of our low p: either a rare event has occurred, or the underlying hypothesis is false. Fisher doesn’t think the former is reasonable, so we should assume the latter (Bakan, 1966).
Note that this procedure is directly trying to measure the truth value of a hypothesis. Lower ps indicate more evidence against the hypothesis. This is based on the Law of Improbability, that is,
Law of Improbability: If hypothesis A implies that the probability that a random variable X takes on the value x is quite small, say p(x), then the observation X = x is evidence against A, and the smaller p(x), the stronger the evidence. (Royall, 1997, p. 65)
In a future post I will attempt to show why this law is not a valid indicator of evidence. For the purpose of this post we just need to understand the logic behind this test and that it is fundamentally different from NP procedures. This test alone does not provide any guidance with regard to taking action or making a decision, it is intended as a measure of evidence against a hypothesis.
Test results would look like this:
The present results obtain a t value of 2.5, which corresponds to an observed p = .01**. This level of significance is very small and indicates quite strong evidence against the hypothesis of no difference.
3. Fisher’s rejection trials
This is a strange twist on both of the other procedures above, taking elements from each to form a rejection trial. This test is a decision procedure, much like NP procedures, but with only one explicitly defined hypothesis, a la p-value significance tests. The test is most like what psychologists actually use today, framed as two possible decisions, again like NP, but now they are framed in terms of only one hypothesis. Rejection regions are back too, defined as a region of values that have small probability under H0 (i.e., defined by a small α). It is framed as a problem of logic, specifically,
…a process analogous to testing a proposition in formal logic via the argument known as modus tollens, or ‘denying the consequent’: if A implies B, then not-B implies not-A. We can test A by determining whether B is true. If B is false, then we conclude that A is false. But, on the other hand, if B is found to be true we cannot conclude that A is true. That is, A can be proven false by such a test but it cannot be proven true — either we disprove A or we fail to disprove it…. When B is found to be true, so that A survives the test, this result, although not proving A, does seem intuitively to be evidence supporting A. (Royall, 1997, p. 72)
An important caveat is that these tests are probabilistic in nature, so the logical implications aren’t quite right. Nevertheless, rejection trials are what Fisher referred to when he famously said,
Every experiment may be said to exist only in order to give the facts a chance of disproving the null hypothesis… The notion of an error of the so-called ‘second kind,’ due to accepting the null hypothesis ‘when it is false’ … has no meaning with reference to simple tests of significance. (Fisher, 1966)
So there is a major difference from NP — With rejection trials you have a single hypothesis (as opposed to 2) combined with decision rules of “reject the H0 or do not reject H0” (as opposed to reject H0/H1 or accept H0/H1). With rejection trials we are back to making a decision. This test is asymmetric (as opposed to NP which is symmetric) — that is, we can only ever reject H0, never accept it.
While we are making decisions with rejection trials, the decisions have a different meaning than that of NP procedures. In this framework, deciding to reject H0 implies the hypothesis is “inconsistent with the data” or that the data “provide sufficient evidence to cause rejection” of the hypothesis (Royall, 1997, p.74). So rejection trials are intended to be both decision procedures and measures of evidence. Test statistics that fall into smaller α regions are considered stronger evidence, much the same way that a smaller p-value indicates more evidence against the hypothesis. For NP procedures α is simply a property of the test, and choosing a lower one has no evidential meaning per se (although see Mayo, 1996 for a 4th significance procedure — severity testing).
Test results would look like this:
The present results obtain a t = 2.5, p = .01, which is sufficiently strong evidence against H0 to warrant its rejection.
What is the takeaway?
If you aren’t aware of the difference between the three types of hypothesis testing procedures, you’ll find yourself jumbling them all up (Gigerenzer, 2004). If you aren’t careful, you may end up thinking you have a measure of evidence when you actually have a guide to action.
Which one is correct?
Funny enough, I don’t endorse any of them. I contend that p-values never measure evidence (in either p-value procedures or rejection trials) and NP procedures lead to absurdities that I can’t in good faith accept while simultaneously endorsing them.
Why write 2000 words clarifying the nuanced differences between three procedures I think are patently worthless? Well, did you see what I said at the top referring to sane researchers?
A future post is coming that will explicate the criticisms of each procedure, many of the points again coming from Royall’s book.
References
Armitage, P., & Berry, G. (1987). Statistical methods in medical research. Oxford: Blackwell Scientific.
Bakan, D. (1966). The test of significance in psychological research.Psychological bulletin, 66(6), 423.
Daniel, W. W. (1991). Hypothesis testing. Biostatistics: a foundation for analysis in the health sciences, 5, 191.
Fisher, R. A. (1958).Statistical methods for research workers (13th ed.). New York: Hafner.
Fisher, R. A. (1966). The design of experiments (8th edn.) Oliver and Boyd.
Gigerenzer, G. (2004). Mindless statistics. The Journal of Socio-Economics,33(5), 587-606.
Mayo, D. G. (1996). Error and the growth of experimental knowledge. University of Chicago Press.
Murphy, E. A. (1985). A companion to medical statistics. Johns Hopkins University Press.
Neyman, J. (1950). First course in probability and statistic. Published by Henry Holt, 1950.,1.
Remington, R. D., & Schork, M. A. (1970). Statistics with applications to the biological and health sciences.
Royall, R. (1997). Statistical evidence: a likelihood paradigm (Vol. 71). CRC press.
Siegel, S. C., & Castellan, J. NJ (1988). Nonparametric statistics for the behavioural sciences. New York, McGraw-Hill.
Snedecor, G. W. WG Cochran. 1980. Statistical Methods. Iowa State Univ. Press, Ames.
Watson, G. S. (1983). Hypothesis testing. Encyclopedia of Statistics in Quality and Reliability.


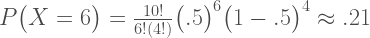


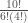 , are equivalent and completely cancel each other out in the likelihood ratio.
, are equivalent and completely cancel each other out in the likelihood ratio.