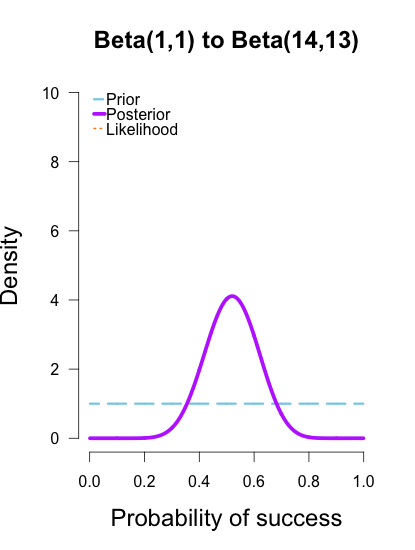
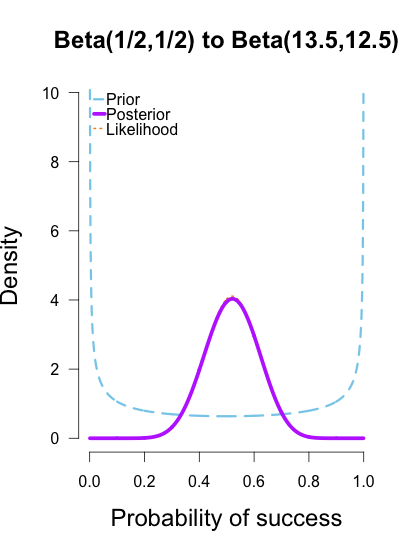
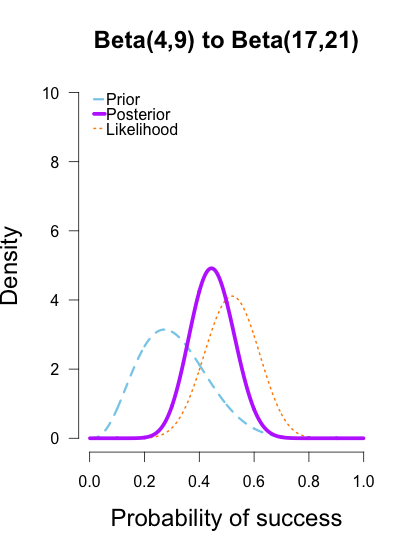
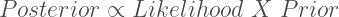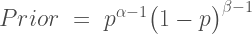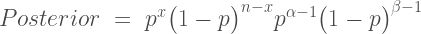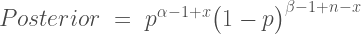It is sometimes considered a paradox that the answer depends not only on the observations but on the question; it should be a platitude.
–Harold Jeffreys, 1939
Joachim Vandekerckhove (@VandekerckhoveJ) and I have just published a Bayesian reanalysis of the Reproducibility Project: Psychology in PLOS ONE (CLICK HERE). It is open access, so everyone can read it! Boo paywalls! Yay open access! The review process at PLOS ONE was very nice; we had two rounds of reviews that really helped us clarify our explanations of the method and results.
Oh and it got a new title: “A Bayesian perspective on the Reproducibility Project: Psychology.” A little less presumptuous than the old blog’s title. Thanks to the RPP authors sharing all of their data, we research parasites were able to find some interesting stuff. (And thanks Richard Morey (@richarddmorey) for making this great badge)

TLDR: One of the main takeaways from the paper is the following: We shouldn’t be too surprised when psychology experiments don’t replicate, given the evidence in the original studies is often unacceptably weak to begin with!
What did we do?
Here is the abstract from the paper:
We revisit the results of the recent Reproducibility Project: Psychology by the Open Science Collaboration. We compute Bayes factors—a quantity that can be used to express comparative evidence for an hypothesis but also for the null hypothesis—for a large subset (N = 72) of the original papers and their corresponding replication attempts. In our computation, we take into account the likely scenario that publication bias had distorted the originally published results. Overall, 75% of studies gave qualitatively similar results in terms of the amount of evidence provided. However, the evidence was often weak (i.e., Bayes factor < 10). The majority of the studies (64%) did not provide strong evidence for either the null or the alternative hypothesis in either the original or the replication, and no replication attempts provided strong evidence in favor of the null. In all cases where the original paper provided strong evidence but the replication did not (15%), the sample size in the replication was smaller than the original. Where the replication provided strong evidence but the original did not (10%), the replication sample size was larger. We conclude that the apparent failure of the Reproducibility Project to replicate many target effects can be adequately explained by overestimation of effect sizes (or overestimation of evidence against the null hypothesis) due to small sample sizes and publication bias in the psychological literature. We further conclude that traditional sample sizes are insufficient and that a more widespread adoption of Bayesian methods is desirable.
In the paper we try to answer four questions: 1) How much evidence is there in the original studies? 2) If we account for the possibility of publication bias, how much evidence is left in the original studies? 3) How much evidence is there in the replication studies? 4) How consistent is the evidence between (bias-corrected) original studies and replication studies?
We implement a very neat technique called Bayesian model averaging to account for publication bias in the original studies. The method is fairly technical, so I’ve put the topic in the Understanding Bayes queue (probably the next post in the series). The short version is that each Bayes factor consists of eight likelihood functions that get weighted based on the potential bias in the original result. There are details in the paper, and much more technical detail in this paper (Guan and Vandekerckhove, 2015). Since the replication studies would be published regardless of outcome, and were almost certainly free from publication bias, we can calculate regular (bias free) Bayes factors for them.
Results
There are only 8 studies where both the bias mitigated original Bayes factors and the replication Bayes factors are above 10 (highlighted with the blue hexagon). That is, both experiment attempts provide strong evidence. It may go without saying, but I’ll say it anyway: These are the ideal cases.
(The prior distribution for all Bayes factors is a normal distribution with mean of zero and variance of one. All the code is online HERE if you’d like to see how different priors change the result; our sensitivity analysis didn’t reveal any major dependencies on the exact prior used.)
The majority of studies (46/72) have both bias mitigated original and replication Bayes factors in the 1/10< BF <10 range (highlighted with the red box). These are cases where both study attempts only yielded weak evidence.

Overall, both attempts for most studies provided only weak evidence. There is a silver/bronze/rusty-metal lining, in that when both study attempts obtain only weak Bayes factors, they are technically providing consistent amounts of evidence. But that’s still bad, because “consistency” just means that we are systematically gathering weak evidence!
Using our analysis, no studies provided strong evidence that favored the null hypothesis in either the original or replication.
It is interesting to consider the cases where one study attempt found strong evidence but another did not. I’ve highlighted these cases in blue in the table below. What can explain this?

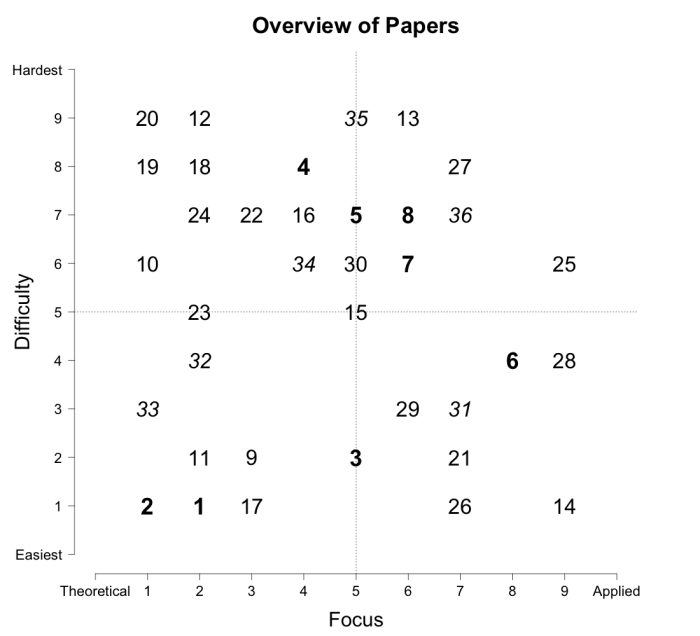
One might be tempted to manufacture reasons that explain this pattern of results, but before you do that take a look at the figure below. We made this figure to highlight one common aspect of all study attempts that find weak evidence in one attempt and strong evidence in another: Differences in sample size. In all cases where the replication found strong evidence and the original study did not, the replication attempt had the larger sample size. Likewise, whenever the original study found strong evidence and the replication did not, the original study had a larger sample size.

Figure 2. Evidence resulting from replicated studies plotted against evidence resulting from the original publications. For the original publications, evidence for the alternative hypothesis was calculated taking into account the possibility of publication bias. Small crosses indicate cases where neither the replication nor the original gave strong evidence. Circles indicate cases where one or the other gave strong evidence, with the size of each circle proportional to the ratio of the replication sample size to the original sample size (a reference circle appears in the lower right). The area labeled ‘replication uninformative’ contains cases where the original provided strong evidence but the replication did not, and the area labeled ‘original uninformative’ contains cases where the reverse was true. Two studies that fell beyond the limits of the figure in the top right area (i.e., that yielded extremely large Bayes factors both times) and two that fell above the top left area (i.e., large Bayes factors in the replication only) are not shown. The effect that relative sample size has on Bayes factor pairs is shown by the systematic size difference of circles going from the bottom right to the top left. All values in this figure can be found in S1 Table.
Abridged conclusion (read the paper for more! More what? Nuance, of course. Bayesians are known for their nuance…)
Even when taken at face value, the original studies frequently provided only weak evidence when analyzed using Bayes factors (i.e., BF < 10), and as you’d expect this already small amount of evidence shrinks even more when you take into account the possibility of publication bias. This has a few nasty implications. As we say in the paper,
In the likely event that [the original] observed effect sizes were inflated … the sample size recommendations from prospective power analysis will have been underestimates, and thus replication studies will tend to find mostly weak evidence as well.
According to our analysis, in which a whopping 57 out of 72 replications had 1/10 < BF < 10, this appears to have been the case.
We also should be wary of claims about hidden moderators. We put it like this in the paper,
The apparent discrepancy between the original set of results and the outcome of the Reproducibility Project can be adequately explained by the combination of deleterious publication practices and weak standards of evidence, without recourse to hypothetical hidden moderators.
Of course, we are not saying that hidden moderators could not have had an influence on the results of the RPP. The statement is merely that we can explain the results reasonably well without necessarily bringing hidden moderators into the discussion. As Laplace would say: We have no need of that hypothesis.
So to sum up,
From a Bayesian reanalysis of the Reproducibility Project: Psychology, we conclude that one reason many published effects fail to replicate appears to be that the evidence for their existence was unacceptably weak in the first place.
With regard to interpretation of results — I will include the same disclaimer here that we provide in the paper:
It is important to keep in mind, however, that the Bayes factor as a measure of evidence must always be interpreted in the light of the substantive issue at hand: For extraordinary claims, we may reasonably require more evidence, while for certain situations—when data collection is very hard or the stakes are low—we may satisfy ourselves with smaller amounts of evidence. For our purposes, we will only consider Bayes factors of 10 or more as evidential—a value that would take an uninvested reader from equipoise to a 91% confidence level. Note that the Bayes factor represents the evidence from the sample; other readers can take these Bayes factors and combine them with their own personal prior odds to come to their own conclusions.
All of the results are tabulated in the supplementary materials (HERE) and the code is on github (CODE HERE).
More disclaimers, code, and differences from the old reanalysis
Disclaimer:
All of the results are tabulated in a table in the supplementary information (link), and MATLAB code to reproduce the results and figures is provided online (CODE HERE). When interpreting these results, we use a Bayes factor threshold of 10 to represent strong evidence. If you would like to see how the results change when using a different threshold, all you have to do is change the code in line 118 of the ‘bbc_main.m’ file to whatever thresholds you prefer.
#######
Important note: The function to calculate the mitigated Bayes factors is a prototype and is not robust to misuse. You should not use it unless you know what you are doing!
#######
A few differences between this paper and an old reanalysis:
A few months back I posted a Bayesian reanalysis of the Reproducibility Project: Psychology, in which I calculated replication Bayes factors for the RPP studies. This analysis took the posterior distribution from the original studies as the prior distribution in the replication studies to calculate the Bayes factor. So in that calculation, the hypotheses being compared are: H_0 “There is no effect” vs. H_A “The effect is close to that found by the original study.” It also did not take into account publication bias.
This is important: The published reanalysis is very different from the one in the first blog post.
Since the posterior distributions from the original studies were usually centered on quite large effects, the replication Bayes factors could fall in a wide range of values. If a replication found a moderately large effect, comparable to the original, then the Bayes factor would very largely favor H_A. If the replication found a small-to-zero effect (or an effect in the opposite direction), the Bayes factor would very largely favor H_0. If the replication found an effect in the middle of the two hypotheses, then the Bayes factor would be closer to 1, meaning the data fit both hypotheses equally bad. This last case happened when the replications found effects in the same direction as the original studies but of smaller magnitude.
These three types of outcomes happened with roughly equal frequency; there were lots of strong replications (big BF favoring H_A), lots of strong failures to replicate (BF favoring H_0), and lots of ambiguous results (BF around 1).
The results in this new reanalysis are not as extreme because the prior distribution for H_A is centered on zero, which means it makes more similar predictions to H_0 than the old priors. Whereas roughly 20% of the studies in the first reanalysis were strongly in favor of H_0 (BF>10), that did not happen a single time in the new reanalysis. This new analysis also includes the possibility of a biased publication processes, which can have a large effect on the results.
We use a different prior so we get different results. Hence the Jeffreys quote at the top of the page.