First and foremost, when testing precise hypotheses, formal use of P-values should be abandoned. Almost anything will give a better indication of the evidence provided by the data against Ho.
After the great response to the eight easy steps paper we posted, I started a recurring series, where each week I highlight one of the papers that we included in the appendix of the paper. The format is short and simple: I will give a quick summary of the paper while sharing a few excerpts that I like. If you’ve read our eight easy steps paper and you’d like to follow along on this extension, I think a pace of one paper per week is a perfect way to ease yourself into the Bayesian sphere. At the end of the post I will list a few suggestions for the next entry, so vote in the comments or on twitter (@alxetz) for which one you’d like next. This paper was voted to be the next in the series.
(I changed the series name to Sunday Bayes, since I’ll be posting these on every Sunday.)
Testing precise hypotheses
This would indicate that say, claiming that a P-value of .05 is significant evidence against a precise hypothesis is sheer folly; the actual Bayes factor may well be near 1, and the posterior probability of Ho near 1/2 (p. 326)
Berger and Delampady (pdf link) review the background and standard practice for testing point null hypotheses (i.e., “precise hypotheses”). The paper came out nearly 30 years ago, so some parts of the discussion may not be as relevant these days, but it’s still a good paper.
They start by reviewing the basic measures of evidence — p-values, Bayes factors, posterior probabilities — before turning to an example. Rereading it, I remember why we gave this paper one of the highest difficulty ratings in the eight steps paper. There is a lot of technical discussion in this paper, but luckily I think most of the technical bits can be skipped in lieu of reading their commentary.
One of the main points of this paper is to investigate precisely when it is appropriate to approximate a small interval null hypothesis by using a point null hypothesis. They conclude, that most of the time, the error of approximation for Bayes factors will be small (<10%),
these numbers suggest that the point null approximation to Ho will be reasonable so long as [the width of the null interval] is one-half a [standard error] in width or smaller. (p. 322)
A secondary point of this paper is to refute the claim that classical answers will typically agree with some “objective” Bayesian analyses. Their conclusion is that such a claim
is simply not the case in the testing of precise hypotheses. This is indicated in Table 1 where, for instance, P(Ho |x) [NB: the posterior probability of the null] is from 5 to 50 times larger than the P-value. (p. 318)
They also review some lower bounds on the amount of Bayesian evidence that corresponds to significant p-values. They sum up their results thusly,
The message is simple: common interpretation of P-values, in terms of evidence against precise [null] hypotheses, are faulty (p. 323)
and
the weighted likelihood of H1 is at most [2.5] times that of Ho. A likelihood ratio [NB: Bayes factor] of [2.5] is not particularly strong evidence, particularly when it is [an upper] bound. However, it is customary in practice to view [p] = .05 as strong evidence against Ho. A P-value of [p] = .01, often considered very strong evidence against Ho, corresponds to [BF] = .1227, indicating that H1 is at most 8 times as likely as Ho. The message is simple: common interpretation of P-values, in terms of evidence against precise [null] hypotheses, are faulty (p. 323)
A few choice quotes
Page 319:
[A common opinion is that if] θ0 [NB: a point null]is not in [a confidence interval] it can be rejected, and looking at the set will provide a good indication as to the actual magnitude of the difference between θ and θ0. This opinion is wrong, because it ignores the supposed special nature of θo. A point can be outside a 95% confidence set, yet not be so strongly contraindicated by the data. Only by calculating a Bayes factor … can one judge how well the data supports a distinguished point θ0.
Page 327:
Of course, every statistician must judge for himself or herself how often precise hypotheses actually occur in practice. At the very least, however, we would argue that all types of tests should be able to be properly analyzed by statistics
Page 327 (emphasis original, since that text is a subheading):
[It is commonly argued that] The P-Value Is Just a Data Summary, Which We Can Learn To Properly Calibrate … One can argue that, through experience, one can learn how to interpret P-values. … But if the interpretation depends on Ho, the sample size, the density and the stopping rule, all in crucial ways, it becomes ridiculous to argue that we can intuitively learn to properly calibrate P-values.
page 328:
we would urge reporting both the Bayes factor, B, against [H0] and a confidence or credible region, C. The Bayes factor communicates the evidence in the data against [H0], and C indicates the magnitude of the possible discrepancy.
Page 328:
Without explicit alternatives, however, no Bayes factor or posterior probability could be calculated. Thus, the argument goes, one has no recourse but to use the P-value. A number of Bayesian responses to this argument have been raised … here we concentrate on responding in terms of the discussion in this paper. If, indeed, it is the case that P-values for precise hypotheses essentially always drastically overstate the actual evidence against Ho when the alternatives are known, how can one argue that no problem exists when the alternatives are not known?
Vote for the next entry:
Edwards, Lindman, and Savage (1963) — Bayesian Statistical Inference for Psychological Research (pdf)
Rouder (2014) — Optional Stopping: No Problem for Bayesians (pdf)
Gallistel (2009) — The Importance of Proving the Null (pdf)
Lindley (2000) — The philosophy of statistics (pdf)
It is sometimes considered a paradox that the answer depends not only on the observations but on the question; it should be a platitude.
–Harold Jeffreys, 1939
Joachim Vandekerckhove (@VandekerckhoveJ) and I have just published a Bayesian reanalysis of the Reproducibility Project: Psychology in PLOS ONE (CLICK HERE). It is open access, so everyone can read it! Boo paywalls! Yay open access! The review process at PLOS ONE was very nice; we had two rounds of reviews that really helped us clarify our explanations of the method and results.
Oh and it got a new title: “A Bayesian perspective on the Reproducibility Project: Psychology.” A little less presumptuous than the old blog’s title. Thanks to the RPP authors sharing all of their data, we research parasites were able to find some interesting stuff. (And thanks Richard Morey (@richarddmorey) for making this great badge)
TLDR: One of the main takeaways from the paper is the following: We shouldn’t be too surprised when psychology experiments don’t replicate, given the evidence in the original studies is often unacceptably weak to begin with!
What did we do?
Here is the abstract from the paper:
We revisit the results of the recent Reproducibility Project: Psychology by the Open Science Collaboration. We compute Bayes factors—a quantity that can be used to express comparative evidence for an hypothesis but also for the null hypothesis—for a large subset (N = 72) of the original papers and their corresponding replication attempts. In our computation, we take into account the likely scenario that publication bias had distorted the originally published results. Overall, 75% of studies gave qualitatively similar results in terms of the amount of evidence provided. However, the evidence was often weak (i.e., Bayes factor < 10). The majority of the studies (64%) did not provide strong evidence for either the null or the alternative hypothesis in either the original or the replication, and no replication attempts provided strong evidence in favor of the null. In all cases where the original paper provided strong evidence but the replication did not (15%), the sample size in the replication was smaller than the original. Where the replication provided strong evidence but the original did not (10%), the replication sample size was larger. We conclude that the apparent failure of the Reproducibility Project to replicate many target effects can be adequately explained by overestimation of effect sizes (or overestimation of evidence against the null hypothesis) due to small sample sizes and publication bias in the psychological literature. We further conclude that traditional sample sizes are insufficient and that a more widespread adoption of Bayesian methods is desirable.
In the paper we try to answer four questions: 1) How much evidence is there in the original studies? 2) If we account for the possibility of publication bias, how much evidence is left in the original studies? 3) How much evidence is there in the replication studies? 4) How consistent is the evidence between (bias-corrected) original studies and replication studies?
We implement a very neat technique called Bayesian model averaging to account for publication bias in the original studies. The method is fairly technical, so I’ve put the topic in the Understanding Bayes queue (probably the next post in the series). The short version is that each Bayes factor consists of eight likelihood functions that get weighted based on the potential bias in the original result. There are details in the paper, and much more technical detail in this paper (Guan and Vandekerckhove, 2015). Since the replication studies would be published regardless of outcome, and were almost certainly free from publication bias, we can calculate regular (bias free) Bayes factors for them.
Results
There are only 8 studies where both the bias mitigated original Bayes factors and the replication Bayes factors are above 10 (highlighted with the blue hexagon). That is, both experiment attempts provide strong evidence. It may go without saying, but I’ll say it anyway: These are the ideal cases.
(The prior distribution for all Bayes factors is a normal distribution with mean of zero and variance of one. All the code is online HERE if you’d like to see how different priors change the result; our sensitivity analysis didn’t reveal any major dependencies on the exact prior used.)
The majority of studies (46/72) have both bias mitigated original and replication Bayes factors in the 1/10< BF <10 range (highlighted with the red box). These are cases where both study attempts only yielded weak evidence.
Overall, both attempts for most studies provided only weak evidence. There is a silver/bronze/rusty-metal lining, in that when both study attempts obtain only weak Bayes factors, they are technically providing consistent amounts of evidence. But that’s still bad, because “consistency” just means that we are systematically gathering weak evidence!
Using our analysis, no studies provided strong evidence that favored the null hypothesis in either the original or replication.
It is interesting to consider the cases where one study attempt found strong evidence but another did not. I’ve highlighted these cases in blue in the table below. What can explain this?
One might be tempted to manufacture reasons that explain this pattern of results, but before you do that take a look at the figure below. We made this figure to highlight one common aspect of all study attempts that find weak evidence in one attempt and strong evidence in another: Differences in sample size. In all cases where the replication found strong evidence and the original study did not, the replication attempt had the larger sample size. Likewise, whenever the original study found strong evidence and the replication did not, the original study had a larger sample size.
Figure 2. Evidence resulting from replicated studies plotted against evidence resulting from the original publications. For the original publications, evidence for the alternative hypothesis was calculated taking into account the possibility of publication bias. Small crosses indicate cases where neither the replication nor the original gave strong evidence. Circles indicate cases where one or the other gave strong evidence, with the size of each circle proportional to the ratio of the replication sample size to the original sample size (a reference circle appears in the lower right). The area labeled ‘replication uninformative’ contains cases where the original provided strong evidence but the replication did not, and the area labeled ‘original uninformative’ contains cases where the reverse was true. Two studies that fell beyond the limits of the figure in the top right area (i.e., that yielded extremely large Bayes factors both times) and two that fell above the top left area (i.e., large Bayes factors in the replication only) are not shown. The effect that relative sample size has on Bayes factor pairs is shown by the systematic size difference of circles going from the bottom right to the top left. All values in this figure can be found in S1 Table.
Abridged conclusion (read the paper for more! More what? Nuance, of course. Bayesians are known for their nuance…)
Even when taken at face value, the original studies frequently provided only weak evidence when analyzed using Bayes factors (i.e., BF < 10), and as you’d expect this already small amount of evidence shrinks even more when you take into account the possibility of publication bias. This has a few nasty implications. As we say in the paper,
In the likely event that [the original] observed effect sizes were inflated … the sample size recommendations from prospective power analysis will have been underestimates, and thus replication studies will tend to find mostly weak evidence as well.
According to our analysis, in which a whopping 57 out of 72 replications had 1/10 < BF < 10, this appears to have been the case.
We also should be wary of claims about hidden moderators. We put it like this in the paper,
The apparent discrepancy between the original set of results and the outcome of the Reproducibility Project can be adequately explained by the combination of deleterious publication practices and weak standards of evidence, without recourse to hypothetical hidden moderators.
Of course, we are not saying that hidden moderators could not have had an influence on the results of the RPP. The statement is merely that we can explain the results reasonably well without necessarily bringing hidden moderators into the discussion. As Laplace would say: We have no need of that hypothesis.
So to sum up,
From a Bayesian reanalysis of the Reproducibility Project: Psychology, we conclude that one reason many published effects fail to replicate appears to be that the evidence for their existence was unacceptably weak in the first place.
With regard to interpretation of results — I will include the same disclaimer here that we provide in the paper:
It is important to keep in mind, however, that the Bayes factor as a measure of evidence must always be interpreted in the light of the substantive issue at hand: For extraordinary claims, we may reasonably require more evidence, while for certain situations—when data collection is very hard or the stakes are low—we may satisfy ourselves with smaller amounts of evidence. For our purposes, we will only consider Bayes factors of 10 or more as evidential—a value that would take an uninvested reader from equipoise to a 91% confidence level. Note that the Bayes factor represents the evidence from the sample; other readers can take these Bayes factors and combine them with their own personal prior odds to come to their own conclusions.
All of the results are tabulated in the supplementary materials (HERE) and the code is on github (CODE HERE).
More disclaimers, code, and differences from the old reanalysis
Disclaimer:
All of the results are tabulated in a table in the supplementary information (link), and MATLAB code to reproduce the results and figures is provided online (CODE HERE). When interpreting these results, we use a Bayes factor threshold of 10 to represent strong evidence. If you would like to see how the results change when using a different threshold, all you have to do is change the code in line 118 of the ‘bbc_main.m’ file to whatever thresholds you prefer.
#######
Important note: The function to calculate the mitigated Bayes factors is a prototype and is not robust to misuse. You should not use it unless you know what you are doing!
#######
A few differences between this paper and an old reanalysis:
A few months back I posted a Bayesian reanalysis of the Reproducibility Project: Psychology, in which I calculated replication Bayes factors for the RPP studies. This analysis took the posterior distribution from the original studies as the prior distribution in the replication studies to calculate the Bayes factor. So in that calculation, the hypotheses being compared are: H_0 “There is no effect” vs. H_A “The effect is close to that found by the original study.” It also did not take into account publication bias.
This is important: The published reanalysis is very different from the one in the first blog post.
Since the posterior distributions from the original studies were usually centered on quite large effects, the replication Bayes factors could fall in a wide range of values. If a replication found a moderately large effect, comparable to the original, then the Bayes factor would very largely favor H_A. If the replication found a small-to-zero effect (or an effect in the opposite direction), the Bayes factor would very largely favor H_0. If the replication found an effect in the middle of the two hypotheses, then the Bayes factor would be closer to 1, meaning the data fit both hypotheses equally bad. This last case happened when the replications found effects in the same direction as the original studies but of smaller magnitude.
These three types of outcomes happened with roughly equal frequency; there were lots of strong replications (big BF favoring H_A), lots of strong failures to replicate (BF favoring H_0), and lots of ambiguous results (BF around 1).
The results in this new reanalysis are not as extreme because the prior distribution for H_A is centered on zero, which means it makes more similar predictions to H_0 than the old priors. Whereas roughly 20% of the studies in the first reanalysis were strongly in favor of H_0 (BF>10), that did not happen a single time in the new reanalysis. This new analysis also includes the possibility of a biased publication processes, which can have a large effect on the results.
We use a different prior so we get different results. Hence the Jeffreys quote at the top of the page.
In the first post of the Understanding Bayes series I said:
The likelihood is the workhorse of Bayesian inference. In order to understand Bayesian parameter estimation you need to understand the likelihood. In order to understand Bayesian model comparison (Bayes factors) you need to understand the likelihood and likelihood ratios.
I’ve shown in another post how the likelihood works as the updating factor for turning priors into posteriors for parameter estimation. In this post I’ll explain how using Bayes factors for model comparison can be conceptualized as a simple extension of likelihood ratios.
There’s that coin again
Imagine we’re in a similar situation as before: I’ve flipped a coin 100 times and it came up 60 heads and 40 tails. The likelihood function for binomial data in general is:
and for this particular result:
The corresponding likelihood curve is shown below, which displays the relative likelihood for all possible simple (point) hypotheses given this data. Any likelihood ratio can be calculated by simply taking the ratio of the different hypotheses’s heights on the curve.
In that previous post I compared the fair coin hypothesis — H0: P(H)=.5 — vs one particular trick coin hypothesis — H1: P(H)=.75. For 60 heads out of 100 tosses, the likelihood ratio for these hypotheses is L(.5)/L(.75) = 29.9. This means the data are 29.9 times as probable under the fair coin hypothesis than this particular trick coin hypothesis. But often we don’t have theories precise enough to make point predictions about parameters, at least not in psychology. So it’s often helpful if we can assign a range of plausible values for parameters as dictated by our theories.
Enter the Bayes factor
Calculating a Bayes factor is a simple extension of this process. A Bayes factor is a weighted average likelihood ratio, where the weights are based on the prior distribution specified for the hypotheses. For this example I’ll keep the simple fair coin hypothesis as the null hypothesis — H0: P(H)=.5 — but now the alternative hypothesis will become a composite hypothesis — H1: P(θ). (footnote 1) The likelihood ratio is evaluated at each point of P(θ) and weighted by the relative plausibility we assign that value. Then once we’ve assigned weights to each ratio we just take the average to get the Bayes factor. Figuring out how the weights should be assigned (the prior) is the tricky part.
Imagine my composite hypothesis, P(θ), is a combination of 21 different point hypotheses, all evenly spaced out between 0 and 1 and all of these points are weighted equally (not a very realistic hypothesis!). So we end up with P(θ) = {0, .05, .10, .15, . . ., .9, .95, 1}. The likelihood ratio can be evaluated at every possible point hypothesis relative to H0, and we need to decide how to assign weights. This is easy for this P(θ); we assign zero weight for every likelihood ratio that is not associated with one of the point hypotheses contained in P(θ), and we assign weights of 1 to all likelihood ratios associated with the 21 points in P(θ).
This gif has the 21 point hypotheses of P(θ) represented as blue vertical lines (indicating where we put our weights of 1), and the turquoise tracking lines represent the likelihood ratio being calculated at every possible point relative to H0: P(H)=.5. (Remember, the likelihood ratio is the ratio of the heights on the curve.) This means we only care about the ratios given by the tracking lines when the dot attached to the moving arm aligns with the vertical P(θ) lines. [edit: this paragraph added as clarification]
The 21 likelihood ratios associated with P(θ) are:
Since they are all weighted equally we simply average, and obtain BF = 18.3/21 = .87. In other words, the data (60 heads out of 100) are 1/.87 = 1.15 times more probable under the null hypothesis — H0: P(H)=.5 — than this particular composite hypothesis — H1: P(θ). Entirely uninformative! Despite tossing the coin 100 times we have extremely weak evidence that is hardly worth even acknowledging. This happened because much of P(θ) falls in areas of extremely low likelihood relative to H0, as evidenced by those 13 zeros above. P(θ) is flexible, since it covers the entire possible range of θ, but this flexibility comes at a price. You have to pay for all of those zeros with a lower weighted average and a smaller Bayes factor.
Now imagine I had seen a trick coin like this before, and I know it had a slight bias towards landing heads. I can use this information to make more pointed predictions. Let’s say I define P(θ) as 21 equally weighted point hypotheses again, but this time they are all equally spaced between .5 and .75, which happens to be the highest density region of the likelihood curve (how fortuitous!). Now P(θ) = {.50, .5125, .525, . . ., .7375, .75}.
The 21 likelihood ratios associated with the new P(θ) are:
They are all still weighted equally, so the simple average is BF = 72/21 = 3.4. Three times more informative than before, and in favor of P(θ) this time! Andno zeros. We were able to add theoretically relevant information to H1 to make more accurate predictions, and we get rewarded with a Bayes boost. (But this result is only 3-to-1 evidence, which is still fairly weak.)
This new P(θ) is risky though, because if the data show a bias towards tails or a more extreme bias towards heads then it faces a very heavy penalty (many more zeros). High risk = high reward with the Bayes factor. Make pointed predictions that match the data and get a bump to your BF, but if you’re wrong then pay a steep price. For example, if the data were 60 tails instead of 60 heads the BF would be 10-to-1 against P(θ) rather than 3-to-1 for P(θ)!
Now, typically people don’t actually specify hypotheses like these. Typically they use continuous distributions, but the idea is the same. Take the likelihood ratio at each point relative to H0, weigh according to plausibilities given in P(θ), and then average.
A more realistic (?) example
Imagine you’re walking down the sidewalk and you see a shiny piece of foreign currency by your feet. You pick it up and want to know if it’s a fair coin or an unfair coin. As a Bayesian you have to be precise about what you mean by fair and unfair. Fair is typically pretty straightforward — H0: P(H)=.5 as before — but unfair could mean anything. Since this is a completely foreign coin to you, you may want to be fairly open-minded about it. After careful deliberation, you assign P(θ) a beta distribution, with shape parameters 10 and 10. That is, H1: P(θ) ~ Beta(10, 10). This means that if the coin isn’t fair, it’s probably close to fair but it could reasonably be moderately biased, and you have no reason to think it is particularly biased to one side or the other.
Now you build a perfect coin-tosser machine and set it to toss 100 times (but not any more than that because you haven’t got all day). You carefully record the results and the coin comes up 33 heads out of 100 tosses. Under which hypothesis are these data more probable, H0 or H1? In other words, which hypothesis did the better job predicting these data?
This may be a continuous prior but the concept is exactly the same as before: weigh the various likelihood ratios based on the prior plausibility assignment and then average. The continuous distribution on P(θ) can be thought of as a set of many many point hypotheses spaced very very close together. So if the range of θ we are interested in is limited to 0 to 1, as with binomials and coin flips, then a distribution containing 101 point hypotheses spaced .01 apart, can effectively be treated as if it were continuous. The numbers will be a little off but all in all it’s usually pretty close. So imagine that instead of 21 hypotheses you have 101, and their relative plausibilities follow the shape of a Beta(10, 10). (footnote 2)
Since this is not a uniform distribution, we need to assign varying weights to each likelihood ratio. Each likelihood ratio associated with a point in P(θ) is simply multiplied by the respective density assigned to it under P(θ). For example, the density of P(θ) at .4 is 2.44. So we multiply the likelihood ratio at that point, L(.4)/L(.5) = 128, by 2.44, and add it to the accumulating total likelihood ratio. Do this for every point and then divide by the total number of points, in this case 101, to obtain the approximate Bayes factor. The total weighted likelihood ratio is 5564.9, divide it by 101 to get 55.1, and there’s the Bayes factor. In other words, the data are roughly 55 times more probable under this composite H1 than under H0. The alternative hypothesis H1 did a much better job predicting these data than did the null hypothesis H0.
The actual Bayes factor is obtained by integrating the likelihood with respect to H1’s density distribution and then dividing by the (marginal) likelihood of H0. Essentially what it does is cut P(θ) into slices infinitely thin before it calculates the likelihood ratios, re-weighs, and averages. That Bayes factor comes out to 55.7, which is basically the same thing we got through this ghetto visualization demonstration!
Take home
The take-home message is hopefully pretty clear at this point: When you are comparing a point null hypothesis with a composite hypothesis, the Bayes factor can be thought of as a weighted average of every point hypothesis’s likelihood ratio against H0, and the weights are determined by the prior density distribution of H1. Since the Bayes factor is a weighted average based on the prior distribution, it’s really important to think hard about the prior distribution you choose for H1. In a previous post, I showed how different priors can converge to the same posterior with enough data. The priors are often said to “wash out” in estimation problems like that. This is not necessarily the case for Bayes factors. The priors you choose matter, so think hard!
Notes
Footnote 1: A lot of ink has been spilled arguing about how one should define P(θ). I talked about it a little a previous post.
Footnote 2: I’ve rescaled the likelihood curve to match the scale of the prior density under H1. This doesn’t affect the values of the Bayes factor or likelihood ratios because the scaling constant cancels itself out.
R code
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I wonder if you’d be ok to help me to understanding this Gelman’s graph. I struggle to understand what is the plotted distribution and the exact meaning of the red area. Of course I read the related article, but it doesn’t help me much.
Rather than write a long-winded email, I figured it will be easier to explain on the blog using some step by step illustrations. With the anonymous reader’s permission I am sharing the question and this explanation for all to read. The graph in question is reproduced below. I will walk through my explanation by building up to this plot piecewise with the information we have about the specific situation referenced in the related paper. The paper, written by Andrew Gelman and John Carlin, illustrates the concepts of Type-M errors and Type-S errors. From the paper:
–
We frame our calculations not in terms of Type 1 and Type 2 errors but rather Type S (sign) and Type M (magnitude) errors, which relate to the probability that claims with confidence have the wrong sign or are far in magnitude from underlying effect sizes (p. 2)
So Gelman’s graph is an attempt to illustrate these types of errors. I won’t go into the details of the paper since you can read it yourself! I was asked to explain this graph though, which isn’t in the paper, so we’ll go through step by step building our own type-s/m graph in order to build an understanding. The key idea is this: if the underlying true population mean is small and sampling error is large, then experiments that achieve statistical significance must have exaggerated effect sizes and are likely to have the wrong sign. The graph in question:
–
–
A few technical details: Here Gelman is plotting a sampling distribution for a hypothetical experiment. If one were to repeatedly take a sample from a population, then each sample mean would be different from the true population mean by some amount due to random variation. When we run an experiment, we essentially pick a sample mean from this distribution at random. Picking at random, sample means tend to be near the true mean of the population, and the how much these random sample means vary follows a curve like this. The height of the curve represents the relative frequency for a sample mean in a series of random picks. Obtaining sample means far away from the true mean is relatively rare since the height of the curve is much lower the farther out we go from the population mean. The red shaded areas indicate values of sample means that achieve statistical significance (i.e., exceed some critical value).
–
The distribution’s form is determined by two parameters: a location parameter and a scale parameter. The location parameter is simply the mean of the distribution (μ), and the scale parameter is the standard deviation of the distribution (σ). In this graph, Gelman defines the true population mean to be 2 based on his experience in this research area; the standard deviation is equal to the sampling error (standard error) of our procedure, which in this case is approximately 8.1 (estimated from empirical data; for more information see the paper, p. 6). The extent of variation in sample means is determined by the amount of sampling error present in our experiment. If measurements are noisy, or if the sample is small, or both, then sampling error goes up. This is reflected in a wider sampling distribution. If we can refine our measurements, or increase our sample size, then sampling error goes down and we see a narrower sampling distribution (smaller value of σ).
Let’s build our own Type-S and Type-M graph
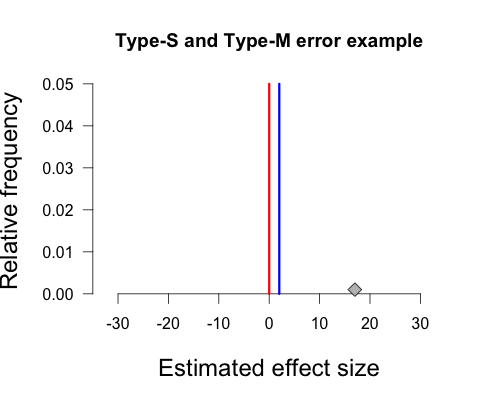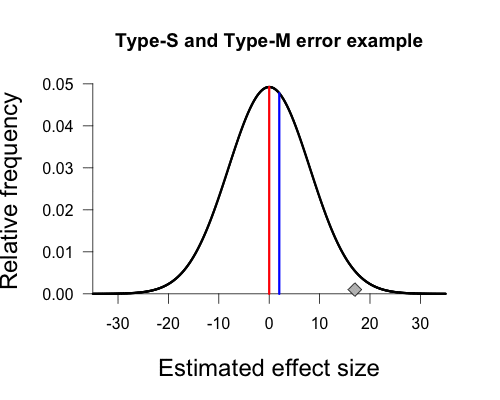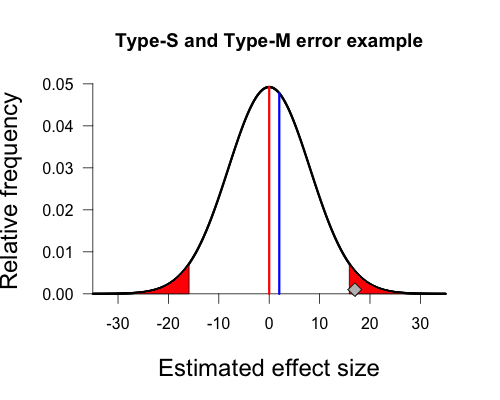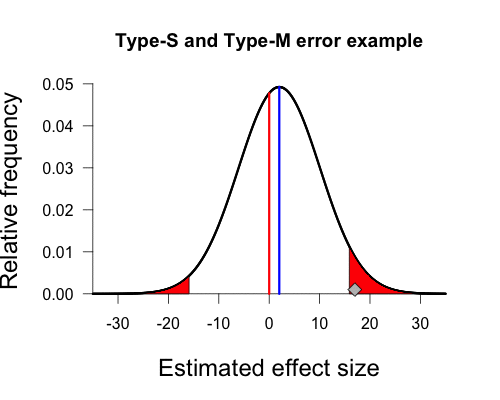
In Gelman’s graph the mean of the population is 2, and this is indicated by the vertical blue line at the peak of the curve. Again, this hypothetical true value is determined by Gelman’s experience with the topic area. The null hypothesis states that the true mean of the population is zero, and this is indicated by the red vertical line. The hypothetical sample mean from Gelman’s paper is 17, which I’ve added as a small grey diamond near the x-axis. R code to make all figures is provided at the end of this post (except the gif).
–
–
If we assume that the true population mean is actually zero (indicated by the red vertical line), instead of 2, then the sampling distribution has a location parameter of 0 and a scale parameter of 8.1. This distribution is shown below. The diamond representing our sample mean corresponds to a fairly low height on the curve, indicating that it is relatively rare to obtain such a result under this sampling distribution.
–
–
Next we need to define cutoffs for statistically significant effects (the red shaded areas under the curve in Gelman’s plot) using the null value combined with the sampling error of our procedure. Since this is a two-sided test using an alpha of 5%, we have one cutoff for significance at approximately -15.9 (i.e., 0 – [1.96 x 8.1]) and the other cutoff at approximately 15.9 (i.e., 0 + [1.96 x 8.1]). Under the null sampling distribution, the shaded areas are symmetrical. If we obtain a sample mean that lies beyond these cutoffs we declare our result statistically significant by conventional standards. As you can see, the diamond representing our sample mean of 17 is just beyond this cutoff and thus achieves statistical significance.
–
–
But Gelman’s graph assumes the population mean is actually 2, not zero. This is important because we can’t actually have a sign error or a magnitude error if there isn’t a true sign or magnitude. We can adjust the curve so that the peak is above 2 by shifting it over slightly to the right. The shaded areas begin in the same place on the x-axis as before (+/- 15.9), but notice that they have become asymmetrical. This is due to the fact that we shifted the entire distribution slightly to the right, shrinking the left shaded area and expanding the right shaded area.
–
–
And there we have our own beautiful type-s and type-m graph. Since the true population mean is small and positive, any sample mean falling in the left tail has the wrong sign and vastly overestimates the population mean (-15.9 vs. 2). Any sample mean falling in the right tail has the correct sign, but again vastly overestimates the population mean (15.9 vs. 2). Our sample mean falls squarely in the right shaded tail. Since the standard error of this procedure (8.1) is much larger than the true population mean (2), any statistically significant result must have a sample mean that is much larger in magnitude than the true population mean, and is quite likely to have the wrong sign.
–
In this case the left tail contains 24% of the total shaded area under the curve, so in repeated sampling a full 24% of significant results will be in the wrong tail (and thus be a sign error). If the true population mean were still positive but larger in magnitude then the shaded area in the left tail would become smaller and smaller, as it did when we shifted the true population mean from zero to 2, and thus sign errors would be less of a problem. As Gelman and Carlin summarize,
setting the true effect size to 2% and the standard error of measurement to 8.1%, the power comes out to 0.06, the Type S error probability is 24%, and the expected exaggeration factor is 9.7. Thus, it is quite likely that a study designed in this way would lead to an estimate that is in the wrong direction, and if “significant,” it is likely to be a huge overestimate of the pattern in the population. (p. 6)
I hope I’ve explained this clearly enough for you, anonymous reader (and other readers, of course). Leave a comment below or tweet/email me if anything is unclear!
–
Here is a neat gif showing our progression! Thanks for reading 🙂
–
(I don’t think this disclaimer is needed but here it goes: I don’t think people should actually use repeated-sampling statistical inference. This is simply an explanation of the concept. Be a Bayesian!)
R code
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
[This post has been updated and turned into a paper to be published in AMPPS]
Much of the discussion in psychology surrounding Bayesian inference focuses on priors. Should we embrace priors, or should we be skeptical? When are Bayesian methods sensitive to specification of the prior, and when do the data effectively overwhelm it? Should we use context specific prior distributions or should we use general defaults? These are all great questions and great discussions to be having.
One thing that often gets left out of the discussion is the importance of the likelihood. The likelihood is the workhorse of Bayesian inference. In order to understand Bayesian parameter estimation you need to understand the likelihood. In order to understand Bayesian model comparison (Bayes factors) you need to understand the likelihood and likelihood ratios.
What is likelihood?
Likelihood is a funny concept. It’s not a probability, but it is proportional to a probability. The likelihood of a hypothesis (H) given some data (D) is proportional to the probability of obtaining D given that H is true, multiplied by an arbitrary positive constant (K). In other words, L(H|D) = K · P(D|H). Since a likelihood isn’t actually a probability it doesn’t obey various rules of probability. For example, likelihood need not sum to 1.
A critical difference between probability and likelihood is in the interpretation of what is fixed and what can vary. In the case of a conditional probability, P(D|H), the hypothesis is fixed and the data are free to vary. Likelihood, however, is the opposite. The likelihood of a hypothesis, L(H|D), conditions on the data as if they are fixed while allowing the hypotheses to vary.
The distinction is subtle, so I’ll say it again. For conditional probability, the hypothesis is treated as a given and the data are free to vary. For likelihood, the data are a given and the hypotheses vary.
The Likelihood Axiom
Edwards (1992, p. 30) defines the Likelihood Axiom as a natural combination of the Law of Likelihood and the Likelihood Principle.
The Law of Likelihood states that “within the framework of a statistical model, a particular set of data supports one statistical hypothesis better than another if the likelihood of the first hypothesis, on the data, exceeds the likelihood of the second hypothesis” (Emphasis original. Edwards, 1992, p. 30).
In other words, there is evidence for H1 vis-a-vis H2 if and only if the probability of the data under H1 is greater than the probability of the data under H2. That is, D is evidence for H1 over H2 if P(D|H1) > P(D|H2). If these two probabilities are equivalent, then there is no evidence for either hypothesis over the other. Furthermore, the strength of the statistical evidence for H1 over H2 is quantified by the ratio of their likelihoods, L(H1|D)/L(H2|D) (which again is proportional to P(D|H1)/P(D|H2) up to an arbitrary constant that cancels out).
The Likelihood Principle states that the likelihood function contains all of the information relevant to the evaluation of statistical evidence. Other facets of the data that do not factor into the likelihood function are irrelevant to the evaluation of the strength of the statistical evidence (Edwards, 1992, p. 30; Royall, 1997, p. 22). They can be meaningful for planning studies or for decision analysis, but they are separate from the strength of the statistical evidence.
Likelihoods are meaningless in isolation
Unlike a probability, a likelihood has no real meaning per se due to the arbitrary constant. Only by comparing likelihoods do they become interpretable, because the constant in each likelihood cancels the other one out. The easiest way to explain this aspect of likelihood is to use the binomial distribution as an example.
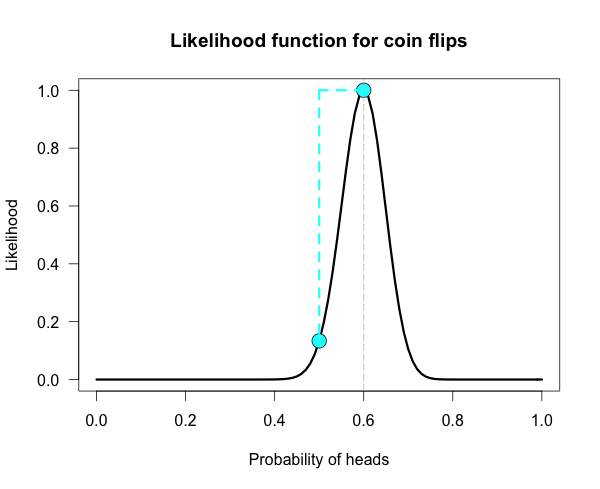
Suppose I flip a coin 10 times and it comes up 6 heads and 4 tails. If the coin were fair, p(heads) = .5, the probability of this occurrence is defined by the binomial distribution:
where x is the number of heads obtained, n is the total number of flips, p is the probability of heads, and
Substituting in our values we get
If the coin were a trick coin, so that p(heads) = .75, the probability of 6 heads in 10 tosses is:
To quantify the statistical evidence for the first hypothesis against the second, we simply divide one probability by the other. This ratio tells us everything we need to know about the support the data lends to one hypothesis vis-a-vis the other. In the case of 6 heads in 10 tosses, the likelihood ratio (LR) for a fair coin vs our trick coin is:
Translation: The data are 1.4 times as probable under a fair coin hypothesis than under this particular trick coin hypothesis. Notice how the first terms in each of the equations above, i.e., , are equivalent and completely cancel each other out in the likelihood ratio.
Same data. Same constant. Cancel out.
The first term in the equations above, , details our journey to obtaining 6 heads out of 10. If we change our journey (i.e., different sampling plan) then this changes the term’s value, but crucially, since it is the same term in both the numerator and denominator it always cancels itself out. In other words, the information contained in the way the data are obtained disappears from the function. Hence the irrelevance of the stopping rule to the evaluation of statistical evidence, which is something that makes bayesian and likelihood methods valuable and flexible.
If we leave out the first term in the above calculations, our numerator is L(.5) = 0.0009765625 and our denominator is L(.75) ≈ 0.0006952286. Using these values to form the likelihood ratio we get: 0.0009765625/0.0006952286 ≈ 1.4,as we should since the other terms simply cancelled out before.
Again I want to reiterate that the value of a single likelihood is meaningless in isolation; only in comparing likelihoods do we find meaning.
Looking at likelihoods
Likelihoods may seem overly restrictive at first. We can only compare 2 simple statistical hypotheses in a single likelihood ratio. But what if we are interested in comparing many more hypotheses at once? What if we want to compare all possible hypotheses at once?
In that case we can plot the likelihood function for our data, and this lets us ‘see’ the evidence in its entirety. By plotting the entire likelihood function we compare all possible hypotheses simultaneously. The Likelihood Principle tells us that the likelihood function encompasses all statistical evidence that our data can provide, so we should always plot this function along side our reported likelihood ratios.
Following the wisdom of Birnbaum (1962), “the “evidential meaning” of experimental results is characterized fully by the likelihood function” (as cited in Royall, 1997, p.25). So let’s look at some examples. The R script at the end of this post can be used to reproduce these plots, or you can use it to make your own plots. Play around with it and see how the functions change for different number of heads, total flips, and hypotheses of interest. See the instructions in the script for details.
Below is the likelihood function for 6 heads in 10 tosses. I’ve marked our two hypotheses from before on the likelihood curve with blue dots. Since the likelihood function is meaningful only up to an arbitrary constant, the graph is scaled by convention so that the best supported value (i.e., the maximum) corresponds to a likelihood of 1.
The vertical dotted line marks the hypothesis best supported by the data. The likelihood ratio of any two hypotheses is simply the ratio of their heights on this curve. We can see from the plot that the fair coin has a higher likelihood than our trick coin.
How does the curve change if instead of 6 heads out of 10 tosses, we tossed 100 times and obtained 60 heads?
Our curve gets much narrower! How did the strength of evidence change for the fair coin vs the trick coin? The new likelihood ratio is L(.5)/L(.75) ≈ 29.9. Much stronger evidence!(footnote) However, due to the narrowing, neither of these hypothesized values are very high up on the curve anymore. It might be more informative to compare each of our hypotheses against the best supported hypothesis. This gives us two likelihood ratios: L(.6)/L(.5) ≈ 7.5 and L(.6)/L(.75) ≈ 224.
Here is one more curve, for when we obtain 300 heads in 500 coin flips.
Notice that both of our hypotheses look to be very near the minimum of the graph. Yet their likelihood ratio is much stronger than before. For this data the likelihood ratio L(.5)/L(.75) is nearly 24 million! The inherent relativity of evidence is made clear here: The fair coin was supported when compared to one particular trick coin. But this should not be interpreted as absolute evidence for the fair coin, because the likelihood ratio for the maximally supported hypothesis vs the fair coin, L(.6)/L(.5), is nearly 24 thousand!
We need to be careful not to make blanket statements about absolute support, such as claiming that the maximum is “strongly supported by the data”. Always ask, “Compared to what?” The best supported hypothesis will be only be weakly supported vs any hypothesis just before or just after it on the x-axis. For example, L(.6)/L(.61) ≈ 1.1, which is barely any support one way or the other. It cannot be said enough that evidence for a hypothesis must be evaluated in consideration with a specific alternative.
Connecting likelihood ratios to Bayes factors
Bayes factors are simple extensions of likelihood ratios. A Bayes factor is a weighted average likelihood ratio based on the prior distribution specified for the hypotheses. (When the hypotheses are simple point hypotheses, the Bayes factor is equivalent to the likelihood ratio.) The likelihood ratio is evaluated at each point of the prior distribution and weighted by the probability we assign that value. If the prior distribution assigns the majority of its probability to values far away from the observed data, then the average likelihood for that hypothesis is lower than one that assigns probability closer to the observed data. In other words, you get a Bayes boost if you make more accurate predictions. Bayes factors are extremely valuable, and in a future post I will tackle the hard problem of assigning priors and evaluating weighted likelihoods.
I hope you come away from this post with a greater knowledge of, and appreciation for, likelihoods. Play around with the R code and you can get a feel for how the likelihood functions change for different data and different hypotheses of interest.
(footnote) Obtaining 60 heads in 100 tosses is equivalent to obtaining 6 heads in 10 tosses 10 separate times. To obtain this new likelihood ratio we can simply multiply our ratios together. That is, raise the first ratio to the power of 10; 1.4^10 ≈ 28.9, which is just slightly off from the correct value of 29.9 due to rounding.
R Code
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters




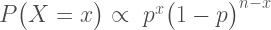












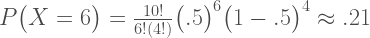


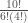 , are equivalent and completely cancel each other out in the likelihood ratio.
, are equivalent and completely cancel each other out in the likelihood ratio.